Blog
May 20, 2021

This guide will explain everything you need to know about how to do load testing. After completing it, you will be able to build a comprehensive plan for testing your application. This guide will explain all the elements and information you need to take into consideration to find and fix those annoying bottlenecks, so you can give your users a better experience when using your application. We’ll also show examples using open-source JMeter and BlazeMeter, but you can use any load testing tools you prefer.
How to Do Load Testing From Beginning to End
1. Design a Performance Testing Plan
After we define which environment will be tested and which tools will be used to develop the scripts and execute them, it’s time to design and define the test plan. This planning document should contain:
- Introduction: A brief overview
- Objective: What is the objective of these load tests and the benefits they will bring
- Scope: The system processes that are going to be tested
- Architecture: Details of the application architecture, like Application Server, Web Server, DB Server, Firewalls, 3rd party applications, etc.
- Prerequisites: All the resources required to start the project, like ensuring all the components that will be load tested are functionally and stable and that the environment is the same as the one that is in production and has (at least) similar data to production
- Test Scenarios: The list of scenarios that are going to be tested
- Load Execution Cycles: Mention the baseline, how many cycles of test runs will be executed, the duration of each cycle and its load
- Team: The team members who will be involved in the scripting and execution of the load tests
2. Create Test Cases
The goal of test cases is to establish the level of performance delivered by the present system. The information gathered is helpful for benchmarking in future. It is recommended that performance test cases cover the critical functionalities of the application. When I say critical, I mean the most used by users. For example, in e-commerce, one critical functionality is the purchase button.
Here are some important factors that should be given adequate consideration when designing your test cases:
- Expected load: The load expected by the application in production
- Assertions: Ensure that the application responds as we expect for each request
- Security: Ensure that the system maintains user confidentiality, data integrity, and authorized permissions.
- Desired Response Time: The total time it takes for a response to be received after initiating a request for it
3. Create Load Scenarios
In load tests, we simulate the workload that an application will have in production. We count the number of concurrent users accessing the application, the test cases that will be executed, and the frequency of executions by users, among other things.
To design a load scenario it’s recommended to consider these variables:
- Daily operations
- Peak hours on the system
- Most popular days used
With these variables you will be able to identify the most used operation/s and the amount of users that are using those operations. So now that you have the necessary information it’s time to create the load scenario in JMeter.
When preparing a performance test, design a load scenario that uses simplifications of the real system usage, in order to improve the cost/benefit ratio. If we were to create an identical simulation to what the system will receive in production, we would end up with such an expensive test that it would not be worth it. The benefits may not be worth the costs and the results may even be obtained after it’s too late!
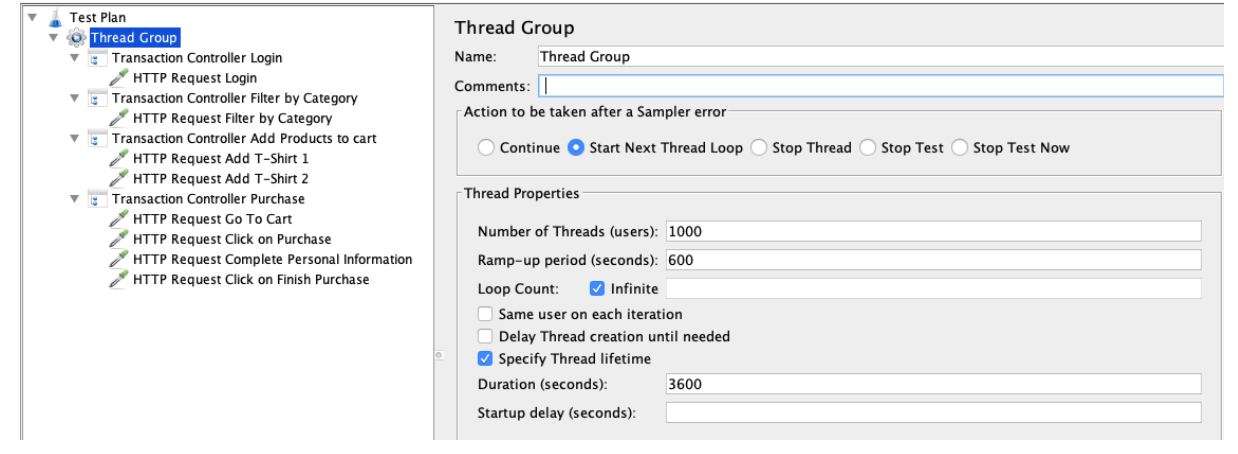
Picture 1 - Tool: JMeter. Load Scenario: Complete workload of a purchase. Number of concurrent users: 1000. Ramp-up: 10 minutes. Execution duration: 1 hour.
4. Identify Infrastructure and Data
It’s highly recommended to know which infrastructure hosts your app and which components are included in the solution. This is useful for understanding the infrastructure and which components need to be monitored during the execution of the tests to gather the necessary information.
To create a more realistic test, data plays an important role in the execution of the tests. So it is recommended that the data amount and data quality/reliability on the testing environment is similar to the one that is in production. This will help simulate “reality” during the test execution.
Let’s see an example. We have two environments with the same infrastructure. The test environment has a database with a small amount of data and the production environment has a database with a lot of data. We send the same request from the front-end. Which response time will be higher? The answer is - the request sent from production. This is because the database that is in production needs more time to process between all the data that contains. As a result, the test is unreliable for real-time usage.
5. Use Acceptance Criteria
Acceptance criteria are the conditions that the test load results must meet to be accepted. Well-written acceptance criteria help avoid unexpected results in production environments and ensure that all stakeholders and users are satisfied with what they get.
Such criteria should be established prior to test runs and are based on what results we expect and require from the application. Some of the most common and important criteria are:
- Response Time
- Error Percentage
- Processor Usage
- Memory Usage
- Disk Usage
6. Execute Tests
During test execution there are some activities that the tester should perform, mainly monitoring the live results and checking engine health. These activities are a crucial component of the test execution phase, essential for the success of the test execution.
You can monitor the results in BlazeMeter.
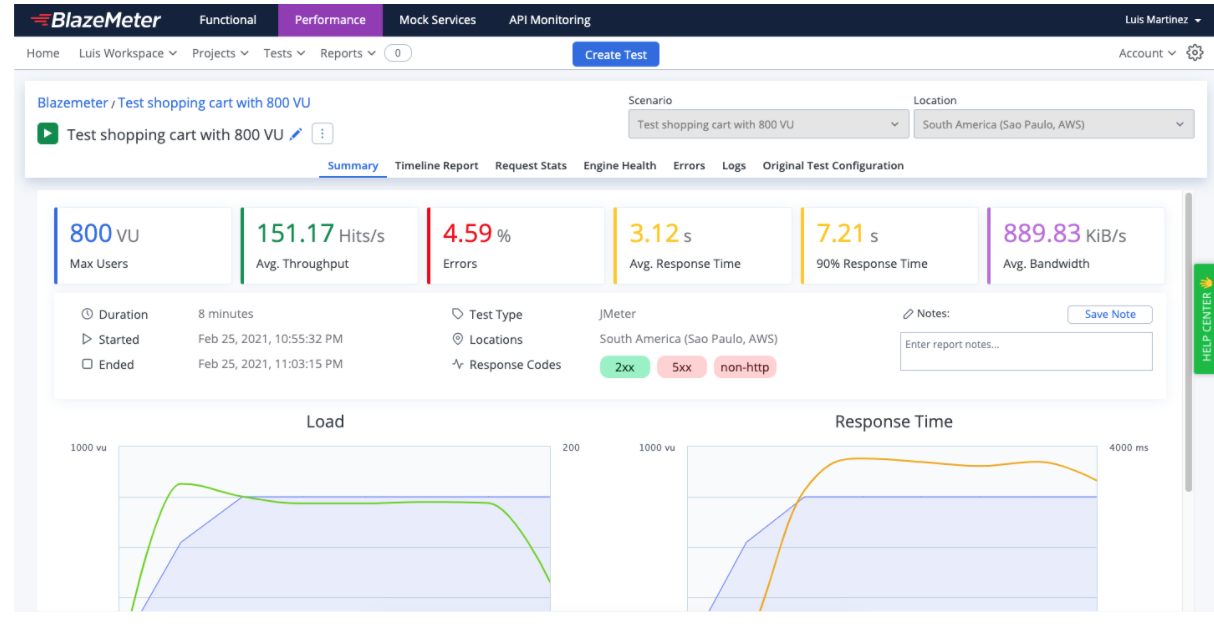
Picture 2 - BlazeMeter summary report of an execution of load test with 800 concurrent virtual users.
It is also recommended to check the Engine health of the engines assigned to the test. This can be done in the “Engine Health” tab (check picture 3). The values of the CPU shouldn’t go over 75% and the memory RAM values 70%. If the values are higher you should consider decreasing the number of virtual users per engine or check the script to make it more efficient. For example, if you have a Beanshell postprocessor you could exchange it with a JSR223 postprocessor, which allows using Groovy language, so the script will be more efficient when running it.
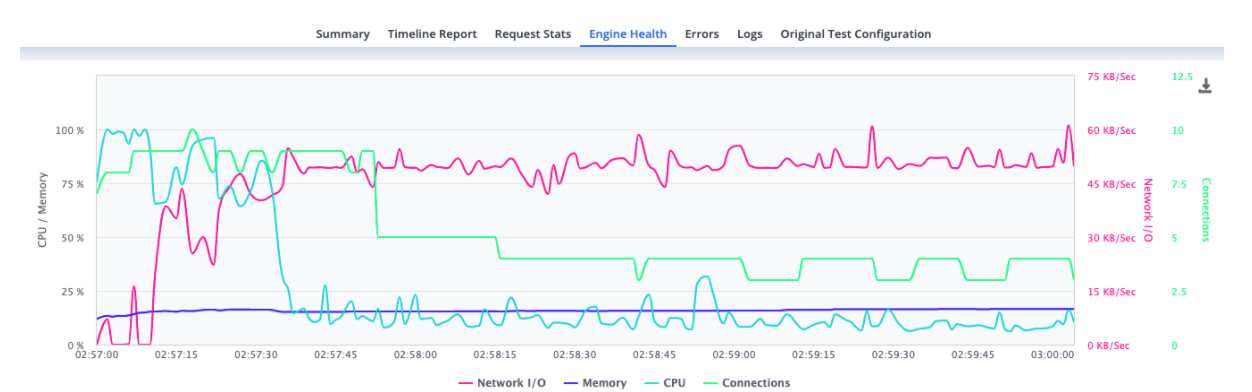
Picture 3 - BlazeMeter Engines Health of an execution of load test with 800 concurrent virtual users.
Back to topOther Considerations For Load Testing
Concurrent Users vs Active Users
We’re often asked about the difference between Concurrent Users and Active Users. Teams want to calculate the numbers they should be shooting for as performance goals, so they need to understand the relationship between these two values.
Concurrent users are users who are engaged with the app. They have an open session but it doesn’t mean that they are performing actions on the app. On the other hand, active users are users who are engaged with the app. They have an open session and they are performing actions on the app.
Test Logs
One of the common answers from a performance tester when something goes wrong in a test is: “Give me some time to check the logs, to make sure we didn’t miss anything”. The reason for this is that we can find everything that happened during the execution of the test in the test logs.
For example, if you need a JMeter plugin to run your test and you didn’t include it on the execution, you will see a warning in the log named JMeter.log saying that the plugin is missing. The warning will look something like this: “WARN: Missing tika-app.jar in classpath. Unable to convert to plain text this kind of document.”
Another example is when the test stopped prematurely. In this case, you should check the bzt.log file to find the reason. The Error lines will be colored red.
BlazeMeter also enables you to check on how your system is performing during a load test through logs. While BlazeMeter’s dashboard will show you response times, throughput rates, HTTP status codes etc., you can also use log entries to investigate the issue and figure out what caused it. Logs can be downloaded and analyzed with different tools.
BlazeMeter’s available logs are:
- bzt.log: This log details all activities performed by the engine. The tail of this log (most recent 200 rows) can be viewed live while the test is running. This capability is really helpful for debugging tests in real time.
- JMeter.log: Much of the content of the jmeter.log is actually included in the bzt.log. The full jmeter.log can be very useful for troubleshooting JMeter-specific issues.
- System.log: The System Log simply gives you a high-level view of the test's life-cycle, from the moment the test starts to when it's terminated.
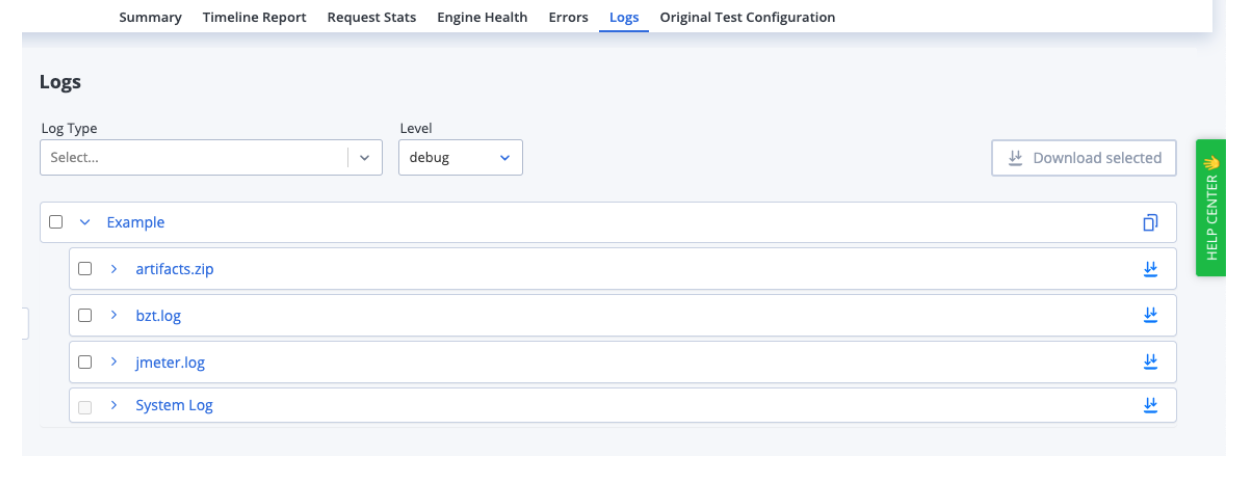
Picture 4 - Blazemeter’s available logs.
You can download the .zip file named artifacts.zip (picture 4) for further analysis. This zip file contains:
- The test script in your test configuration - either a script you uploaded or a script BlazeMeter auto-generated in order to run your test.
- A copy of the script that shows any modifications BlazeMeter made prior to running it. The file name will have a modified_ prefix.
- Various Taurus YAML files - if you uploaded your own YAML configuration file, it will appear here, along with additional versions showing any modifications BlazeMeter made to it. If you did not upload a YAML, BlazeMeter will auto-generate its own.
- The bzt.log. This is the same one you can view individually.
- Various log files generated by whichever testing tool you had opted to run the test with.
- If you run a JMeter test, JTL files containing the results of the test run will be included. These can be handy for debugging if you load them into a View Results Tree or similar listener in JMeter.
- Any additional files you might have used for that test run (such as CSV data files, for example).
One thing to keep in mind is that if you terminate the test instead of shutting it down gracefully, or if the test ended prematurely in an unexpected manner, the artifacts.zip will not be generated.
Incremental Test Executions
The best practice approach for load testing is an incremental, meaning the load is increased gradually. It’s recommended to start the test with 25% of the expected load for the application. Then, continue with 50% of load, 75% of the load and finally, if everything goes well, execute the test with 100% of the expected load.
This method is helpful because we can’t be sure that the application will be able to hold the expected load. By adding loads in an incremental manner, we will be able to find errors or bottlenecks in the application earlier in the process.
We will also have the information about the percentage of the load that is causing these errors, saving us the effort of continuing with other executions until we solve these problems.
Analyzing Test Results
Performance test result analysis is an important and technical part of performance testing. It requires analyzing the graphs, checking metrics, discovering bottlenecks, comparing results with the baseline, and concluding the test results.
Let’s show an example of analyzing test results with the summary report that BlazeMeter brings:
Picture 5 - BlazeMeter summary report of a load test execution with 800 concurrent virtual users.
In this summary report we can see that the percentage of errors (the ratio of bad responses out of all responses received) is pretty high. A best practice is less than 1%. If the execution presents a higher percentage we should discard that execution, check the errors, solve them and start a new load execution.
We should also check the 90 percentile of response time (the top average value of the first 90% of all samples.). In this case we can see that the 90 percentile is 7.21 seconds. We know that 7.21 seconds is high if we are trying to offer a good user experience, but it’s important to check the acceptance criteria determined beforehand.
The average throughput (the average number of HTTP/s requests per second that are generated by the test) and the average bandwidth (the average bandwidth consumption in megabytes per second generated by the test) are relevant metrics and should be set in the acceptance criteria. So when the time to compare those metrics we have a reference of what is expected.
Now, let’s analyze a visual graph.
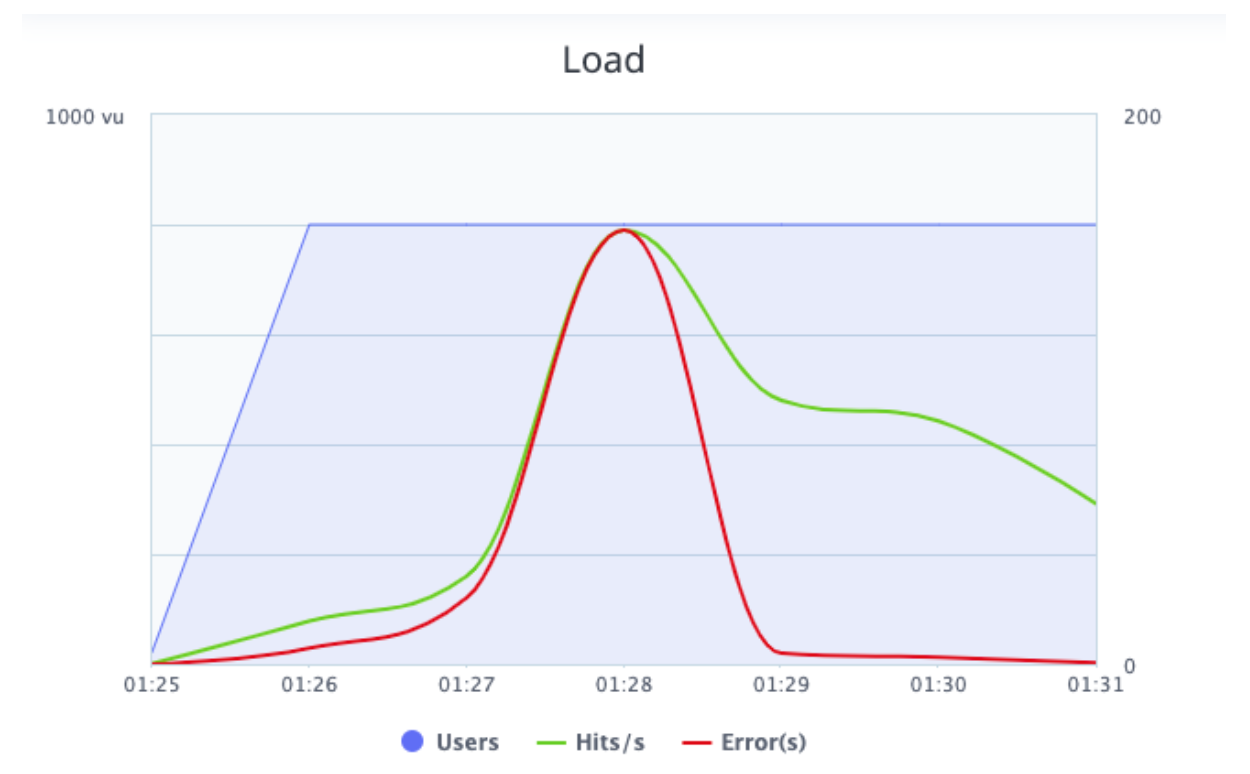
Picture 6 - BlazeMeter load graph.
The load graph shows the hits per second (in green), the errors (in red) and the number of concurrent users (in blue) during the execution.
We can see that while the number of concurrent users increased, the hits per second also increased. This is expected behaviour, because with more users interacting with the application at the same time there will be more requests. In this graph we can also review the errors and when these errors happened. The graph shows that most of the errors happened when the hits per seconds was higher than the rest of the execution. This requires developer attention.
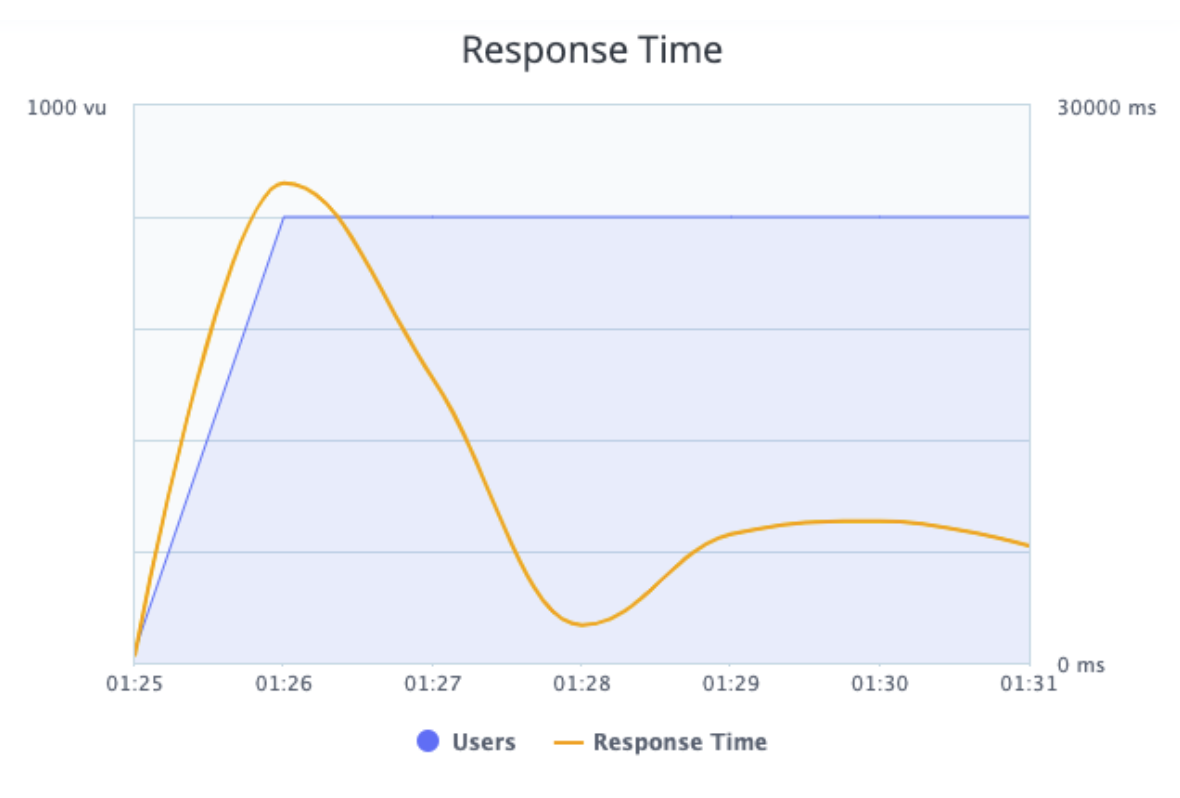
Picture 7 - BlazeMeter Response Time graph.
The response time graph shows the response time (in yellow) and the number of concurrent users (in blue) during the execution.
We can see that while the number of concurrent users increased, the response time initially increased as well.
We can also see that at 01:27 the number of concurrent users stayed the same, but the response time was lower. If we compare the two graphs (Load and Response Time) we can notice that at 01:27 the server began to respond with errors and wasn’t processing the requests, which is the reason why the response time is lower. This requires developer attention.
That's it! We’ve covered all the important elements required for setting up and running a performance testing plan. Now is your turn to apply this knowledge in future projects or in your own app. To get more information about BlazeMeter and JMeter try out our free BlazeMeter University.