Get the load testing best practices you need to drive success. In this blog, we break down everything you need to know.
Why You Need Load Testing
Load testing checks how systems function while a heavy volume of concurrent virtual users perform transactions over a period of time. In other words, load testing tests how systems handle heavy load volumes. There are a few types of open-source load testing tools that serve this purpose, JMeter being the most popular.
Let’s explore the key best practices for load testing your site under both everyday and peak traffic conditions.
Back to top
Load Testing Best Practices
Here are the top three load testing best practices:
Test Early and Test Often
Catch and fix failures well before you expect your peak load event. Allow a minimum 90 days prior to go-live in order to have time to test all scenarios. This way, you’re not just checking a box to say “I did it,” but you’re actually allowing time to fix bugs and bottlenecks, then run additional tests to verify improvements.
Test the Right Things
Build a checklist of the key performance indicators (KPIs) you want to test so that you only test what’s needed to create a realistic load scenario. There’s no point checking for a million users if your site will never get hit by more than 10,000. Focus on KPIs that ensure your site will perform as smoothly as expected for your audience.
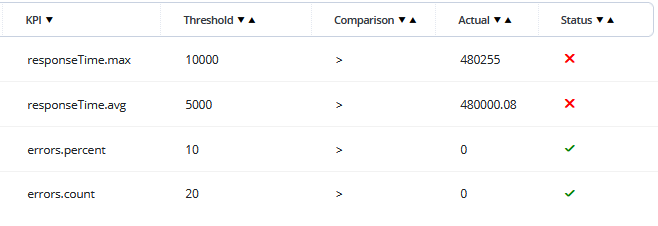
KPIs ensure you're not just going through the motions, but actually verifying that specific requirements (such as response times and error percentages) are met from both an SLA and business standpoint.
BlazeMeter’s pass/fail flagging system is based on a variety of configurable criteria.
For example, your application may pass some performance tests despite slow performance due to the tests having no response time threshold configured. Consider instead a threshold in which the test will fail if the average response time is greater than five seconds. Tests with carefully configured thresholds ensure your users experience fast and reliable performance.
Protect Your Reputation and Revenue
A web service outage can cost hundreds of thousands of dollars and can harm your reputation. Customers want easy access. They will go elsewhere if your site does not perform to expectations. Avoid these nightmare scenarios by testing your system under different loads beforehand. Ensure response times stay low and watch for memory leaks.

Back to top
When and How to Use Load Testing Best Practices
We recommend running both small tests after each build and larger tests for specific events when your site will be put under extra stress, such as Black Friday.
Small load tests ensure code changes don’t affect the everyday user. It’s not enough to test at the end of the process; test continuously so you can find and fix bottlenecks before it’s too late. Check for metrics such as the average load on the site and the average time a single user spends on it.
Run large, maximum-load tests before peak events to ensure your infrastructure is prepared for known problems and to monitor end user experience. Release a maintenance notice, then run these tests during traffic downtime (Sunday at 2:00am, for example) so that real users aren’t affected. If you can’t test in production, create a replica that is as similar as possible.
While your application is under a large load, verify what the end user sees. Have a single frontend user capture metrics, such as page load time, that provide a clear picture of both server performance and end user experience. The world’s fastest response times hardly matter if the user never sees certain page objects.
Back to top
What Type of Load Test Should You Run?
There are a number of types of load and performance tests to consider. Let’s briefly explore some of these types and when they are applicable.
📕 Related Resource: Learn more about How to Run Vegeta Load Testing in BlazeMeter
Long Soak Tests
A peak event such as Black Friday isn’t over in an hour; in fact, it may last a full day or more. You should identify any memory leaks or sluggish queues beforehand. A soak test is essentially an endurance test that strains your system over time to ensure it can properly recycle resources such as CPU, memory, threads, and connections.
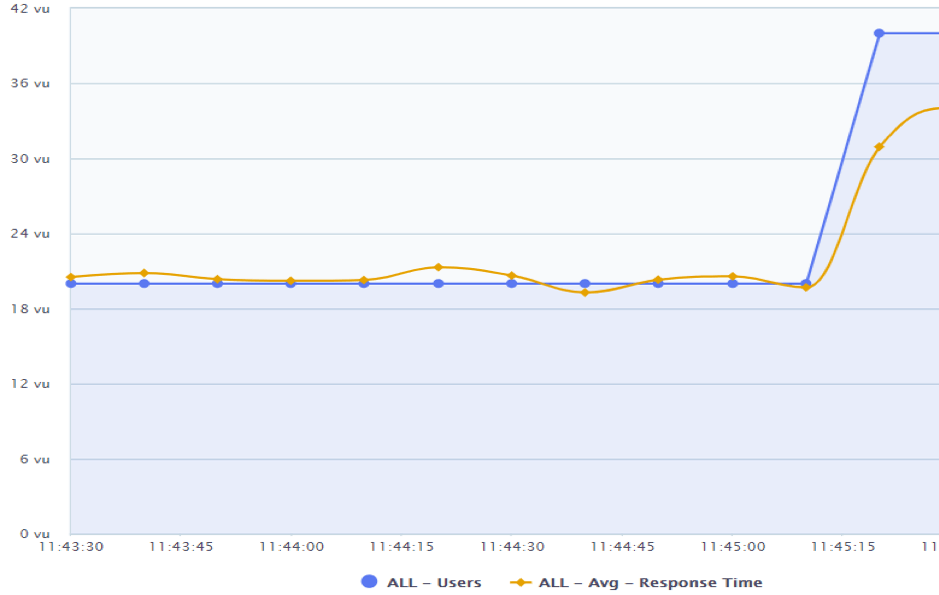
Spike Tests
If you want to verify how your system will react to a sudden ramp-up of virtual users, then you need to run a spike test. This type of test monitors your site’s response to a sudden jump in the amount of concurrent users and how well it recovers afterward.
Failure Point Test
Don’t stop at simply testing anticipated scenarios; take it one step further and determine where exactly your system will fail by pushing it to its maximum limit. Even if you don’t expect that many users, it’s important to test your breaking point and see that the system can recover from it. Be ready for the unexpected.
Back to top
How to Identify Peak Load Times
The best place to start is by having a discussion with your entire team, from marketing to product to R&D, about when peak events will occur. Plan ahead to identify which parts of the application will be stressed. Consider, for example, that if a competitor’s site goes down, it might cause a flood of traffic to yours.
All these factors are impossible to guess, so of course it’s difficult to pre-determine when, why, and how your system will fail. Industry standards suggest that systems are considered under load if 80% of resources are utilized, and you should test at least 20% over your expected peak. The various metrics discussed previously will help you plan.
Even if you think you can anticipate what type of traffic your site will experience on a peak day, other factors are nonetheless unpredictable. Keep an eye on your server logs to view the history of web requests, including client IP address, dates, times, and page requests.
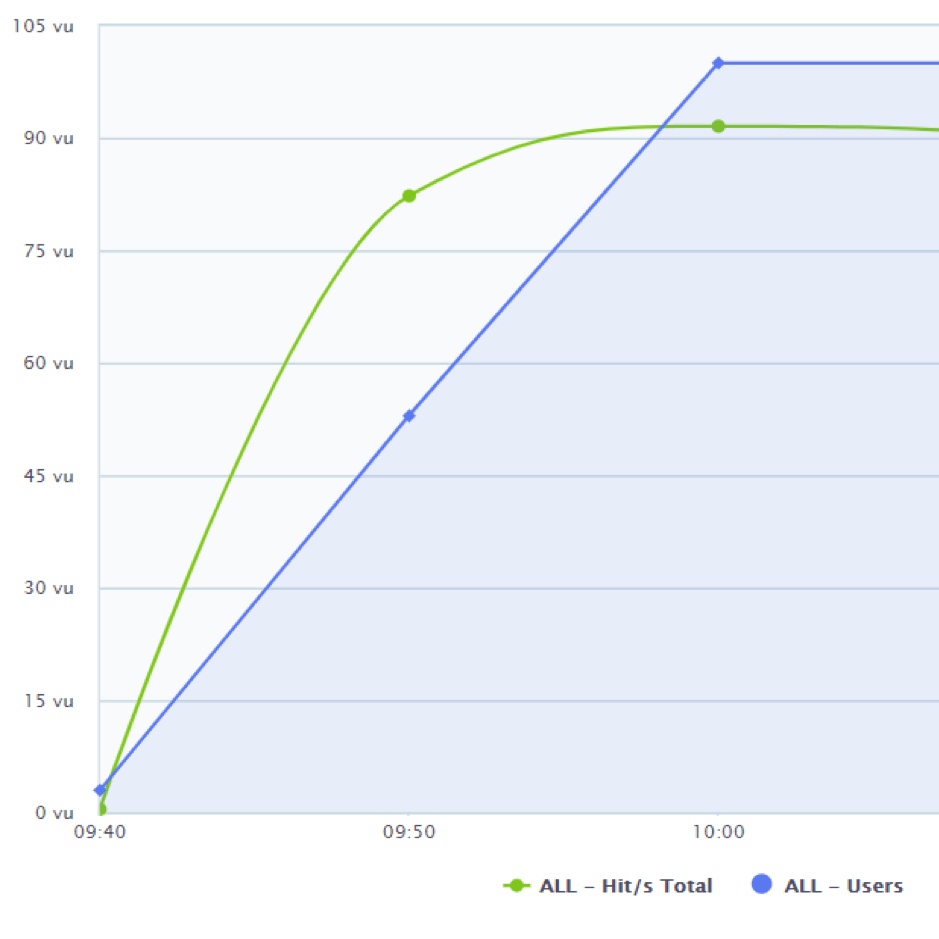
Consider the example graph above. The system under test reaches capacity at about 90 virtual users, at which point the hits per second metric flattens. By discussing these metrics with your entire technical team, you can plan ahead and put together a mitigation procedure if this number is ever reached. Then you can precisely define your current state and where to focus your future goals. (If you test your production environment, remember to notify your users of the maintenance window beforehand.)
Back to top
Creating a Great Load Scenario
Now that you’ve determined what type of test to run and when to run it, the next step is to focus on the type of journeys your various users will undertake. You will need to replicate that journey in order to build a realistic load scenario.
The User Journey
What kind of journeys do your users take? Instead of testing an ideal “happy path”, monitor your customers’ behavior during peak events, then replicate and test those journeys.
For example, once you have identified the saturation point, cross-reference that information with APM data to check if anything is missing or contradictory. This will enrich your understanding of how users behave on your website. (By the way, BlazeMeter can easily integrate with DX APM, New Relic, AppDynamics, Dynatrace, AWS IAM, and CloudWatch.)
Look for bottlenecks and otherwise high stress points where user traffic spiked. Chart trends where your system was close to its limit. For example, if you put a popular product on sale, you may expect a high enough volume on that one page to crash the entire system. The best practice is to divide your system into logical sections based on observed trends, then test them individually to help identify the weakest link.
Where Users Come From
Where do all of your various users come from? Load testers often only test their infrastructure from inside the organization, which is a mistake. Testing external infrastructure is crucial. If you fail to test it, your delivery chains cannot anticipate a peak user day.
Where Users Drop Off
Another common mistake is to assume each user will fully complete their actions in a system. Users often abandon actions due to external interruptions or distractions, so it’s important to test such scenarios. For example, test a user adding something to their cart, only to never check out. You need to know how your system will react.
Ramping Up and Ramping Down
Ramp-up is the amount of time it will take to add all test users to a test execution. Configure it to be slow enough that you have enough time to determine at what stage problems begin.
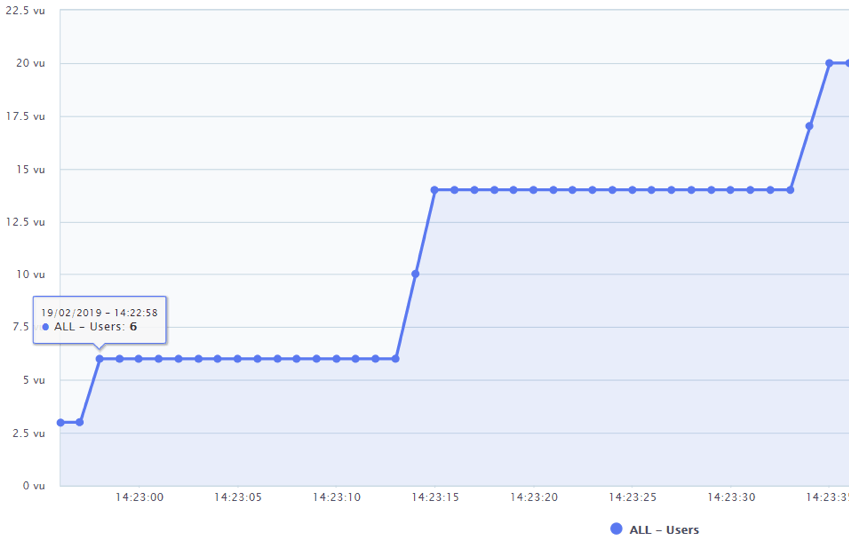
Start at 10% of your peak load, then slowly ramp up. Monitor indicators at each stage.
Next, identify your total capacity, then run load tests at 80% of that total. Monitor your KPIs and how your system reacts. Ensure everything is perfectly stable at 80%. Memory capacity should be mellow, CPU low, and recovery from spikes quick. If something seems jittery at this point, you certainly won’t be able to count on it at 100% load.
If the test failed, identify bottlenecks and errors and fix what needs fixing before testing your system again. If it succeeded, slowly climb up to 100%.
Once you’ve reached full capacity, it’s time to test the load you actually anticipate based on previous user patterns, trend analysis, product requirements, and expected events. Check for memory leaks, high CPU usage, unusual server behavior, and any errors during these tests.
Back to top
How to Run Your Load Test
It’s now time to calibrate and run your load test!
Test the Test
First and foremost, make sure your newly configured test works. You won’t get far if the test fails due to a critical flaw in its configuration. For example, BlazeMeter’s Debug Test can validate your test’s configuration by running a low-scale version of it.
Calibrate the Test
You should ensure none of your test resources are over- or under-utilized by performing a calibration procedure to validate that performance test resources are not causing a bottleneck.
For example, whether running a test on the cloud or your own local hardware, it’s important to not accidentally place so much load on the test engine (machine) that it crashes, stopping the test dead in its tracks. Proper calibration will ensure your testing resources are fully up for the task.
Thorough test calibration is easily a topic to itself. We provide a detailed calibration walkthrough guide for calibrating both JMeter tests and Taurus tests to ensure they run smoothly on BlazeMeter.
Eliminate Bottlenecks
Now you’re ready to run your performance test at your planned load. Your first test runs will be all about finding and fixing bottlenecks. The graph below shows what a bottleneck can look like. Observe how the purple “hits per second” graph dips as the gold “response time” graph spikes.
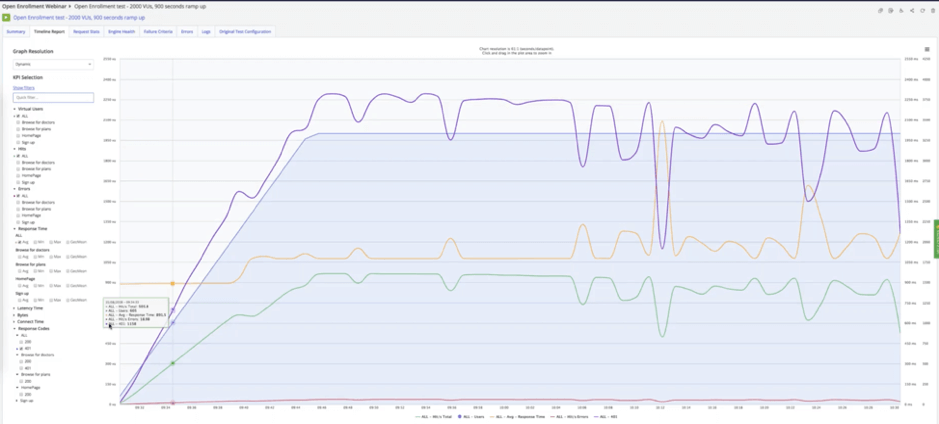
Such an event often means your application server experienced a failure while under load, which will require investigating your application server to find out what happened. This grants you the opportunity to fix issues well ahead of time. Depending on the scenario, you may, for example, need to implement database replication or a failover procedure to ensure your services stay up and running while issues are addressed behind the scenes.
Rerun Tests
Always be better safe than sorry. Each time you fix or improve something, re-run your tests as an extra measure of verification. Test, tweak, test, and test again.
Back to top
Apply Load Testing Best Practices Today
High-performance applications will continue requiring faster and more flexible systems as technology advances. Leverage automation to seamlessly update and run tests. Test early and often in your development life cycles. Prepare a backup plan with backup servers and locations at the ready.
Remember that a solid load testing strategy involves running both smaller tests within your development cycle and larger stress tests in preparation for heavy usage events.
To get started with load testing, simply put your URL into the box below to run a load test on BlazeMeter’s continuous testing platform.