Blog
February 18, 2021

It is important to carefully choose your load testing tools. JMeter is the most popular open-source load and software performance testing tool.
This blog post will offer a basic JMeter tutorial, which will be simple to follow so teams can get started right away. We will create a few basic JMeter scripts and go over different JMeter features like assertions and dynamic data. In the end, we will briefly talk about analyzing your results in reports.
What is JMeter & How Is It Used?
JMeter is open-source and JAVA-based, and simulates the results of browser behavior (though it’s not a browser!) by sending requests to web or application servers. JMeter can also parse the responses. On your local machine, you can increase the load by scaling up to approximately several hundreds of users.
Note that using BlazeMeter, you can scale your load up much, much further, testing thousands or even millions of virtual users in the cloud.
Back to top
Performance Testing With BlazeMeter & JMeter Tutorial: Your First Steps
1. Your First Script
To start off our JMeter tutorial, you first need to download JMeter.
This is the JMeter interface:
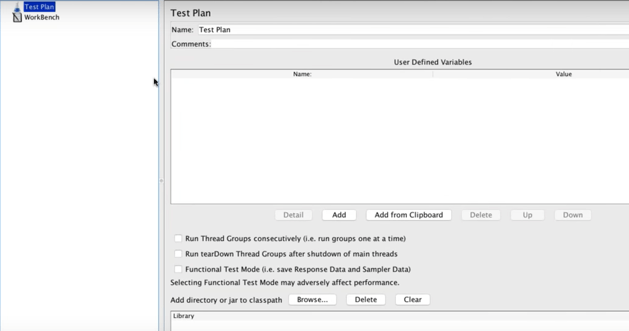
The Test Plan is your JMeter script. It determines the flow of your load test.
In this JMeter tutorial, we will load test the demo we always use at BlazeMeter, which simulates a mock travel agency named Simple. The Simple Travel Agency lets us search and choose flights, which we will simulate doing through JMeter. Our first script will simply search for available flights.
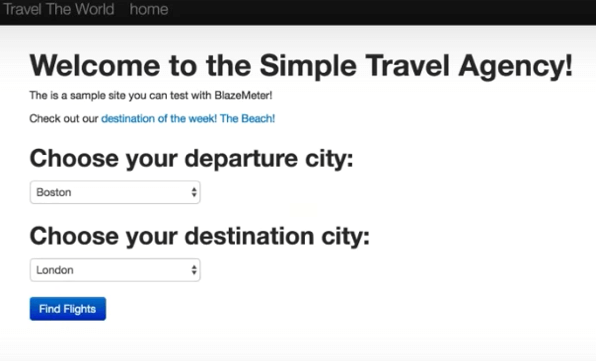
Thread Groups
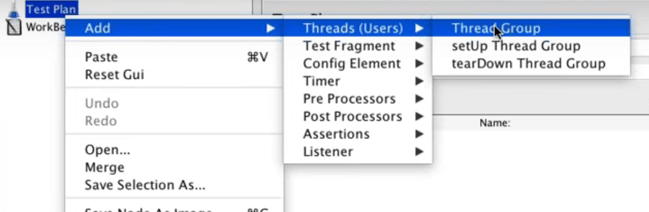
To start building the test script, add a Thread Group to your test plan.
Thread groups determine the user flow and simulate how users behave on the app. Each thread represents a user.
Right click the Test Plan, select "Threads(Users)", then select "Thread Group".
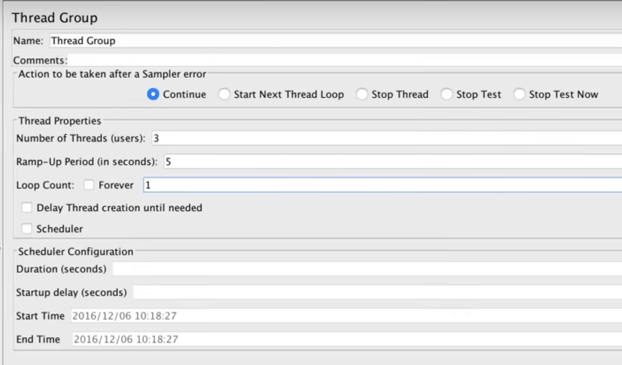
Configure the Thread Group by setting:
- Name: Provide a custom name or, if you prefer, simply leave it named the default “Thread Group”.
- Number of Threads: The number of users (threads) you are testing. Let’s say 3.
- Ramp-up Period: How quickly (in seconds) you want to add users. For example, if set to zero, all users will begin immediately. If set to 10, one user will be added at a time until the full amount is reached at the end of the ten seconds. Let’s say 5 seconds.
- Loop Count: How many times the test should repeat. Let’s say 1 time (no repeats).
Samplers
We want to send an HTTP request to our demo site, so add an HTTP Request Sampler.
Right-click the thread group, select “Add”, select “Sampler”, then select “HTTP Request”.
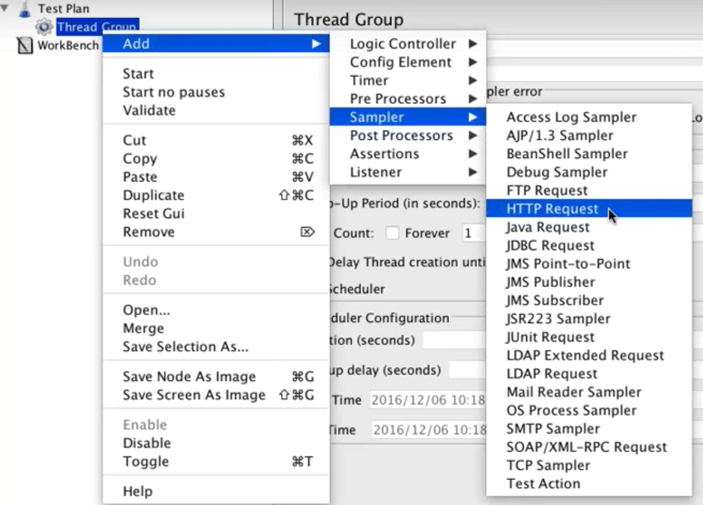
Configure the Sampler by setting:
- Name: Provide a custom name or simply leave it named the default “HTTP Request”.
- Server Name or IP: The server’s DNS name or IP address. In this case - blazedemo.com.
- Set the protocol to “https” as the websites which are accessible only via HTTP are marked as insecure by browsers and excluded from search engine results.
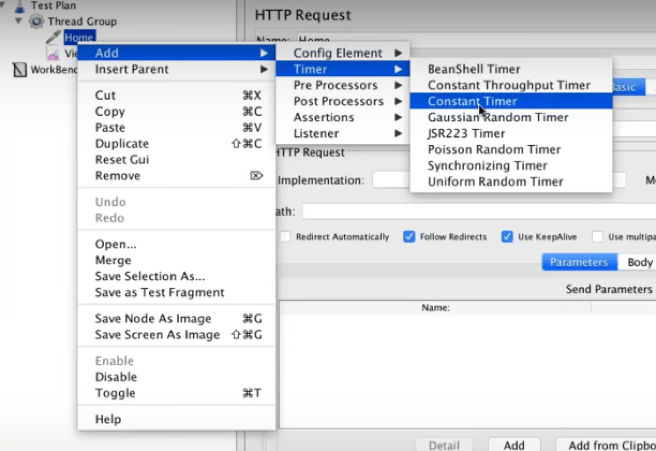
Timers
When users click on your website or app, they naturally have pauses and delays. These can be simulated with Timers.
Constant timers are the most common. They determine how many milliseconds to wait between requests.
Right-click your HTTP Request, select “Add”, select “Timer”, then select “Constant Timer”
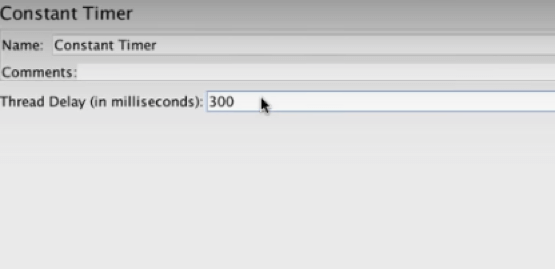
In this case, we will wait for 300 milliseconds.
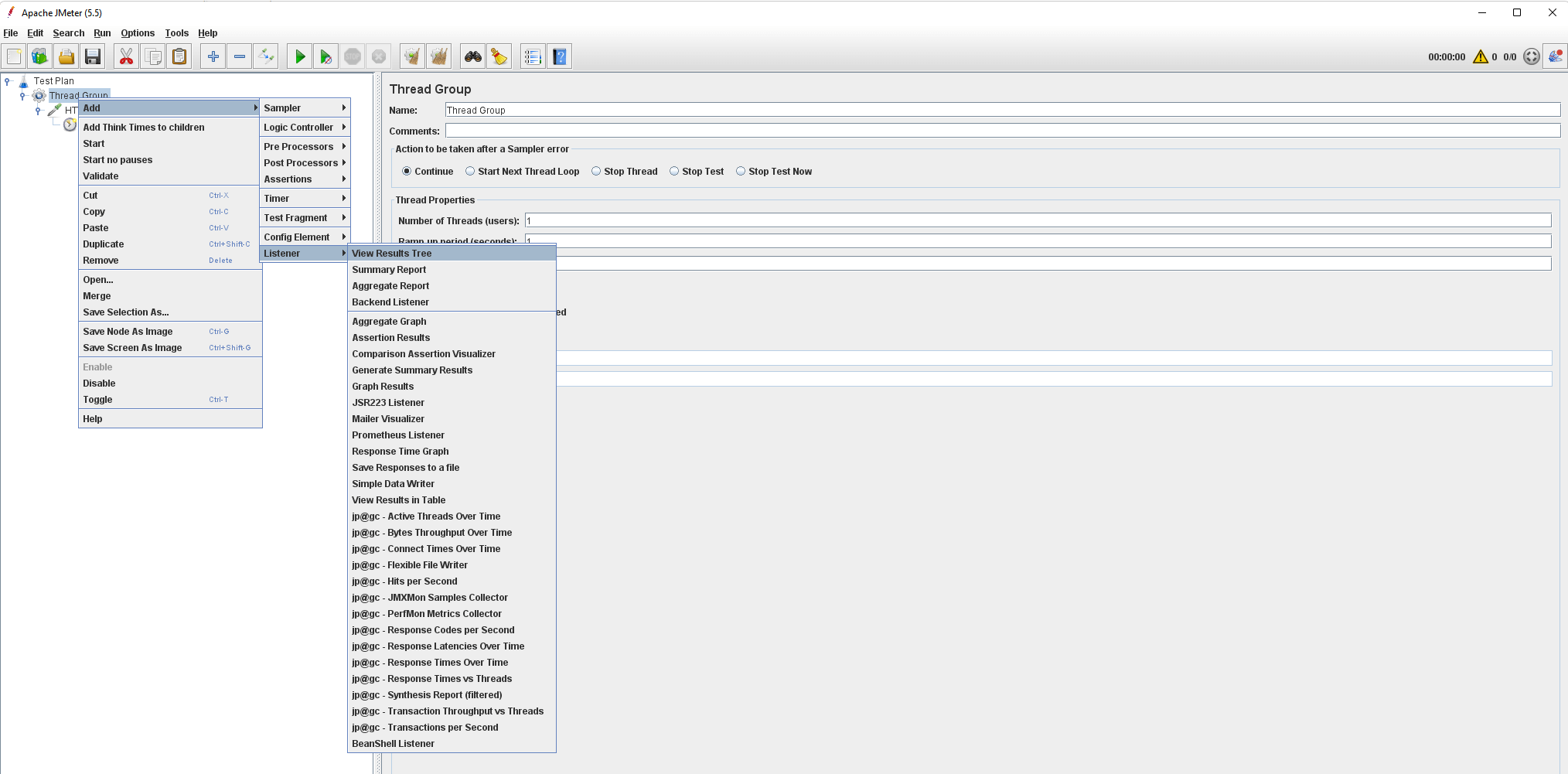
Listeners
After running our test, we want to see its results (obviously). This is done through Listeners, a recording mechanism that shows results, including logging and debugging information.
The View Results Tree is the most common Listener.
Right-click your thread group, select “Add”, select “Listener”, then select “View Results Tree”.
We’re done! This is the basic script we created for hitting the BlazeDemo page:
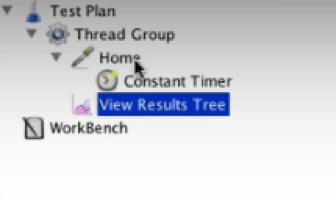
Now click ‘Save’. Your test will be saved as a .jmx file.
To run the test, click the green arrow on top. After the test completes running, you can view the results on the Listener.
In this example, you can see the tests were successful because the results show green icons. On the right, you can see more detailed results, like load time, connect time, errors, the request data, the response data, etc. You can also save the results if you want to.
2. Your Second Script
Congratulations! That was your first script. Now let’s continue this JMeter tutorial by creating a second one and adding parameters to it. Whereas the first script simply searched for flights, this script will search, then choose a flight.
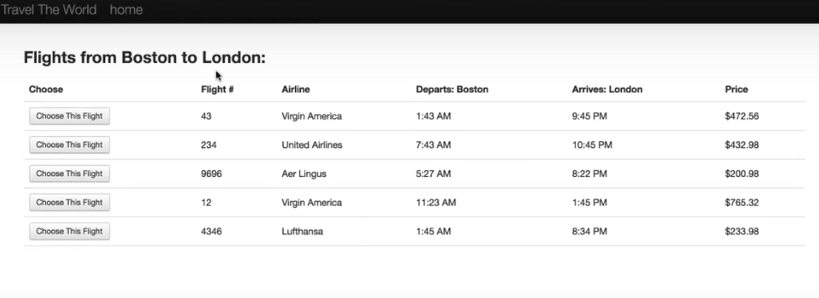
How do you simulate that?
When you search for a flight in your web browser, and click the “Choose This Flight” button beside the flight of your choice, note that the next page adds a “/reserve.php” to the URL.
With this in mind, go back to JMeter and add another HTTP Sampler. This time, we’ll not only specify “blazedemo.com”, but we’ll add “reserve.php” to the “Path” field. Doing so tells the sampler to build a full URL of “blazedemo.com/reserve.php”.
Next, add the parameters required to make the selection. (If you don’t already know what parameters your webpage is designed to use for this scenario, you can use your web browser’s developer tools to review the page code and find it. That is a separate topic to cover another day). To complete the choice, this page requires we specify a “fromPort” and “toPort”, which we’ll designate “Boston” and “London”, respectively:
We’ll also add a “View Results in Table” Listener, just to spice things up.
This is the second test plan, which includes hitting the Home page, and then sending two parameters to the Reserve page.
Save and run the test.
In the results, you can see that each page is hit 3 times:
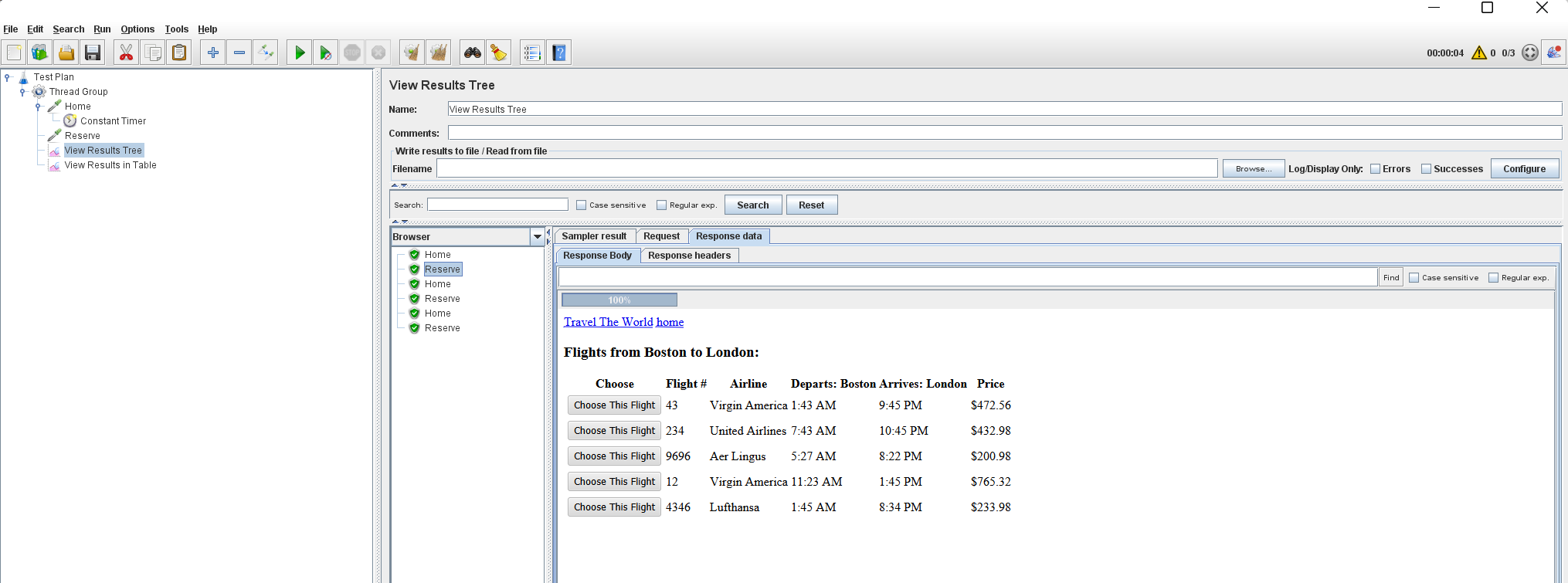
The View Results Table shows us additional data: start time, sent bytes, connect time, latency, etc.
3. Your Third Script
Congratulations! You can now create your own basic JMeter scripts. But as you might have understood, if you need to create a long user flow, it could take you a long time.
Therefore, a better way to create scripts is by recording them. To record, you can either use the JMeter recorder, or the BlazeMeter Chrome Extension. The BlazeMeter extension, free to use from the Chrome store, is more user friendly than the JMeter one, which requires you to set a proxy to redirect the traffic.
Through your Chrome, start recording and simulate the user scenario you want to test by clicking away. When you’re done, stop the recording, and edit as necessary.
Export your recording to JMX. Don’t forget to move the downloaded script to your preferred folder.

Open the .jmx file file in JMeter. You will be able to see your test plan, which was created from the recording and the .jmx file.
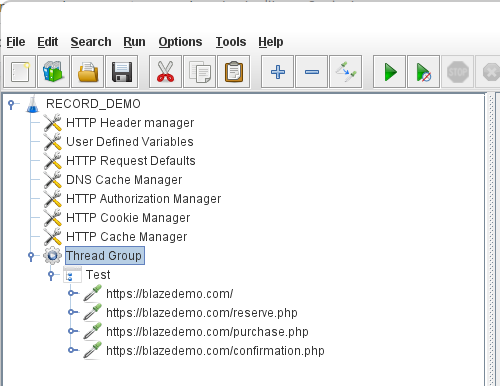
Note that this plan has new elements, like Cookie Manager and Cache Manager. They are here because browsers keep cookies and cache, and they were captured in the recording. You can clear them up if you need to. These entirely optional elements are present to simulate web browser behavior more closely.
Now add a listener and run the test.
Assertions
Assertions are elements that let you check for errors, or in other words - determine if your test passes or fails. JMeter automatically marks requests with HTTP status codes below 400 as successful, but it might be the case that server responded with HTTP status code 200 OK but the response is full of errors or simply absent.
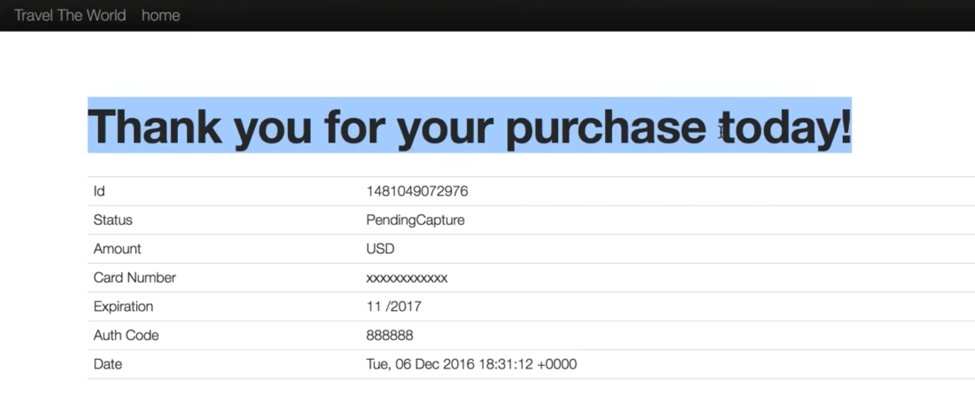
Let’s say we want to make sure a webpage returns the information we’re looking for. In our example, we want to make sure users who purchase flights receive a message on the confirmation page saying - Thank you for your purchase today!
Go to JMeter.
Add a Response Assertion (you know how to do it).
Add the exact characters you want users to see.
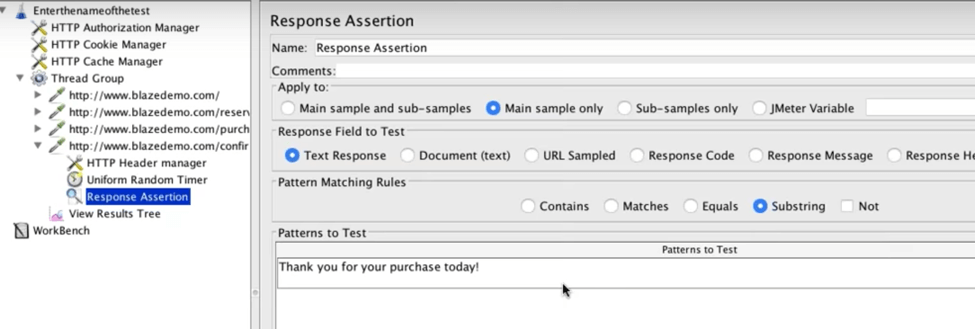
Save and run the test.
If the response contains the string, the test will pass. If not, the test will fail, and it will also detail why.
Dynamic Data
What happens when you want to create a dynamic script, which chooses different parameters each time you test, like passwords, login information, or search criteria? This is what Dynamic Data through CSV files is for.
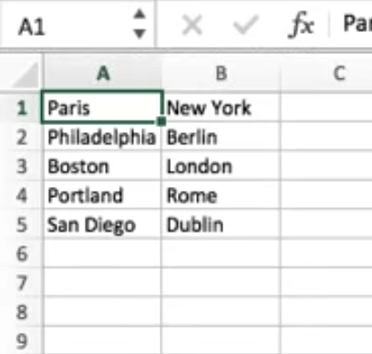
Create a CSV file on your computer, consisting of the different variables you are testing. Put the file in the JMeter folder. In our case, we created a basic one, with departure and destination cities.
Right-click your thread group, select Add, select Config Element, then select CSV Data Set Config.
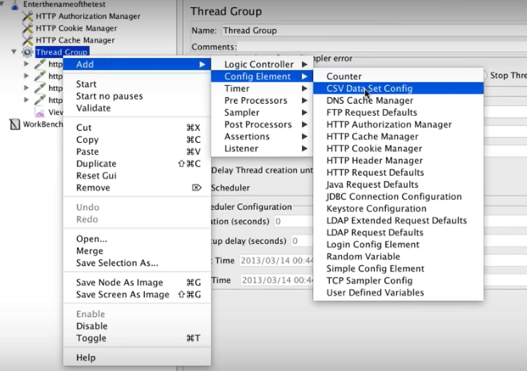
Configure by adding the variable names. In our case, fromPort and toPort.
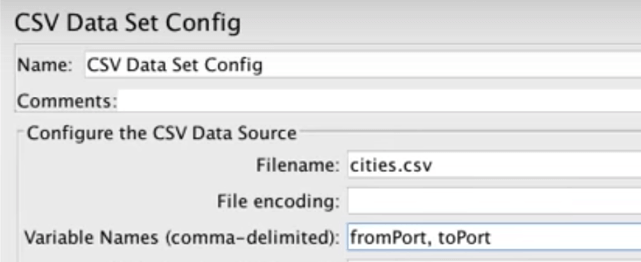
Go back to the HTTP Request (from our second script) and change the variable from the specific name (of the cities) to the general name.
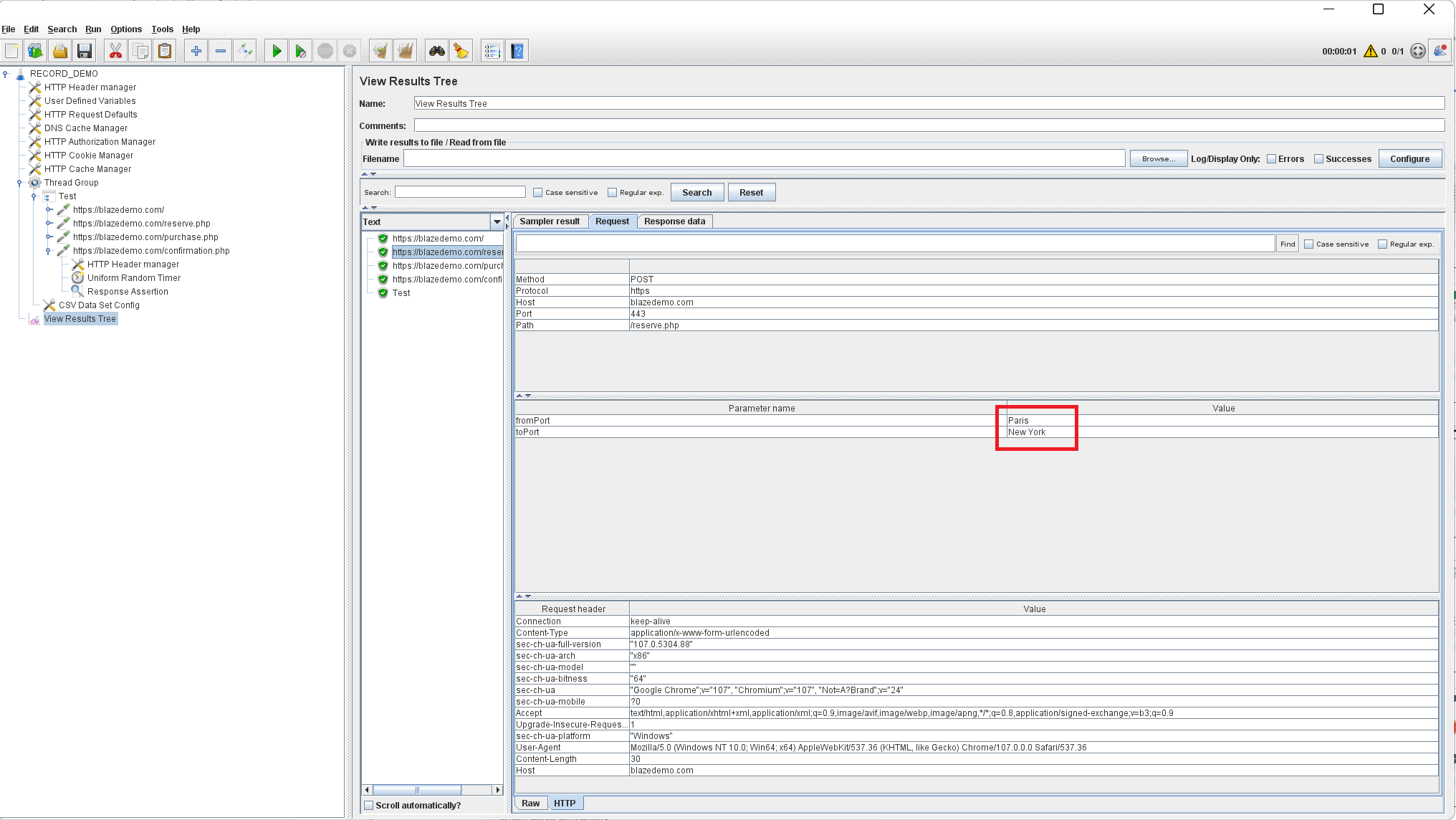
The data tested will now come from the CSV file, and you will be able to see the dynamic results in the View Results Tree. In our example, it’s no longer Boston and London, but Philadelphia and Berlin, Portland and Rome, etc.
Scalability
After you build your test and check it for a low number of virtual users, it’s time to scale it up and check a large number of VUs. How many? That depends on your business goals.
In general, we recommend that in addition to your expected number of users, you bring your test to the limit. This lets you characterize your system’s strengths and weaknesses, enabling you to plan better and also react in real-time to unexpected bottlenecks and errors. Testing the website against anticipated number of users is known as “load testing” and finding the boundaries is a “stress testing” check.
The best way to scale is through BlazeMeter, which lets you run heavier loads than JMeter. BlazeMeter lets you upload your JMeter scripts, scale your number of users, choose your region, set ramp-up time and determine how long the test will run.
Back to topAnalyzing Results of Your JMeter Tutorial
After running your test on BlazeMeter, you will get rich and in-depth reports, with KPIs like throughput, error rate, and connection time. Reports let you analyze trends and statistics, determine the health of your system, and decide how you want to keep developing your product.
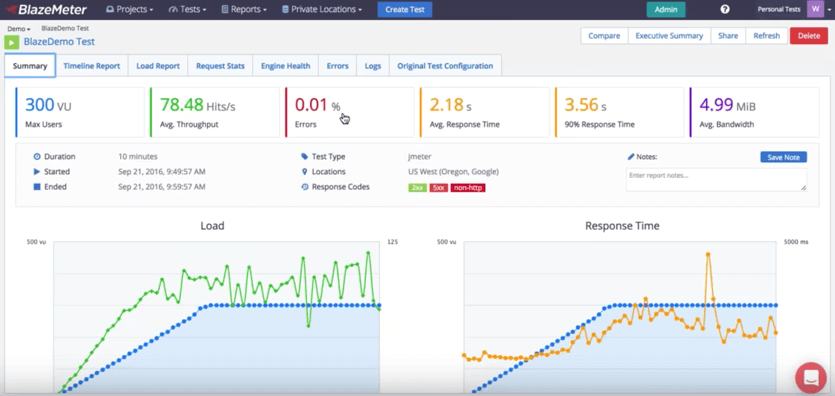
In addition there is extra powerful Timeline Report which gives you ability to correlate any metrics you can think of. And it’s also possible to compare reports for different test executions.
Congratulations! You just finished your basic JMeter tutorial. Now, get started testing yourself in BlazeMeter.