Blog
August 25, 2020

The largest risk when releasing a new version to production is finding errors and issues, small or large, a moment after the release. Even if you thoroughly test the new features on your load testing environments, they might behave differently in production, causing malfunctions and glitches.
But there is a solution: blue-green deployment is a risk-reducing method for deploying new versions to production. This is done by working with two identically configured environments, one production (publicly facing) and one internal, and switching between them.
This blog will give an overview of blue-green deployment and testing, and share five best practices for ensuring that the process goes smoothly.
What Is a Blue Green Deployment?
A blue-green deployment is a development strategy that uses two identical environments for testing. One (green) is a live production environment, while the other (blue) is a dev environment that can only be accessed within the organization itself.
The Blue/Green naming is just a way to distinguish between two separate environments: Because the same environment can serve as production one day and as non-production the other, we need to refer to them with a constant naming, regardless of the role they play. Some refer to it as A/B deployments, some call it Red/Black, etc. It doesn’t really matter, as long as everyone is talking about the same thing.
Green and Blue are connected to the same database, are configured almost identically, and behave the same way. The only difference is that one is a live production environment (let’s say the Green one) and all your users are using it, while the other one (Blue) is open only internally, to the organization.
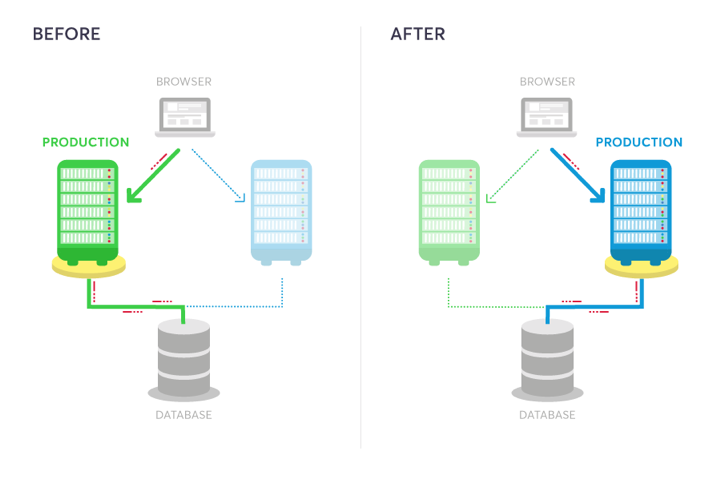
How Blue Green Deployment & Blue Green Testing Works
First, we deploy our release candidate version on the Blue (internal) environment, after passing dev/qa tests. Remember this is a release candidate, so minimal quality gates should be checked before it is dubbed “release candidate”.
Then, we use our internally facing environment to run the last set of tests, either manual or automated functional tests. If bugs are found they are fixed immediately and deployed.
Once the new release is confirmed and after ensuring everything is working properly on the Blue environment, a “switch” process takes place: Blue becomes live production instead of Green, and Green becomes internal. This is a seamless process for the user, who isn’t even aware the version has changed.
In any case, if something wrong is detected on Green, you can always instantly switch back to Blue, which is still up with the previous version. This process is repeated every release, and each time environments switch from production to internal and vice versa.
For example, let’s say you added a new feature using a new query to the database. In your testing environments, the dataset is rather small. During your tests, you may not notice the query is taking a long time to execute because you forgot to add an index to your database.
When you release to production, if the production dataset is larger, you will see slowness in your app right away. But now it’s too late - the code is already in production and your users are already using it. If adding this missing index takes time - your only options are either to roll back your change or patiently wait for the index to get created. To avert that risk, you can use Blue-Green deployment.
Now that we understand how Blue-Green deployment and testing works, let’s cover some best practices for implementing it.
Back to topBlue-Green Deployment Best Practices
1. Choose Load Balancing Over DNS Switching
When switching between environments, you need to make your domain to eventually point to different servers. Don’t go to the DNS records and make changes in the DNS management interface. It can take browsers a long time, even hours, until they get the new IP address. This is called “propagation time” and it will result in a long traffic “tail” (clients still addressing the old servers) to your previous environment .
This means that some of your users will still be served by the old environment, and that you are not in full control where your traffic is routed to.
Instead, use load balancing. Load balancers enable you to set your new servers immediately, without having to depend on the DNS mechanism. The DNS record will always point to the Load Balancer - and you only change the servers behind it. This way you can be absolutely sure that all traffic comes to the new production environment instead of the old one.
2. Execute a Rolling Update
Switching all your servers from an old version to a new one at once may result in downtime.
To avoid that, you can execute a “rolling update”. This means that instead of switching from all Blue servers to all Green servers in a single cut-off, you can work with an integrated environment. Add one new server, retire one old server, and repeat this until all the new servers are inside (see image below):
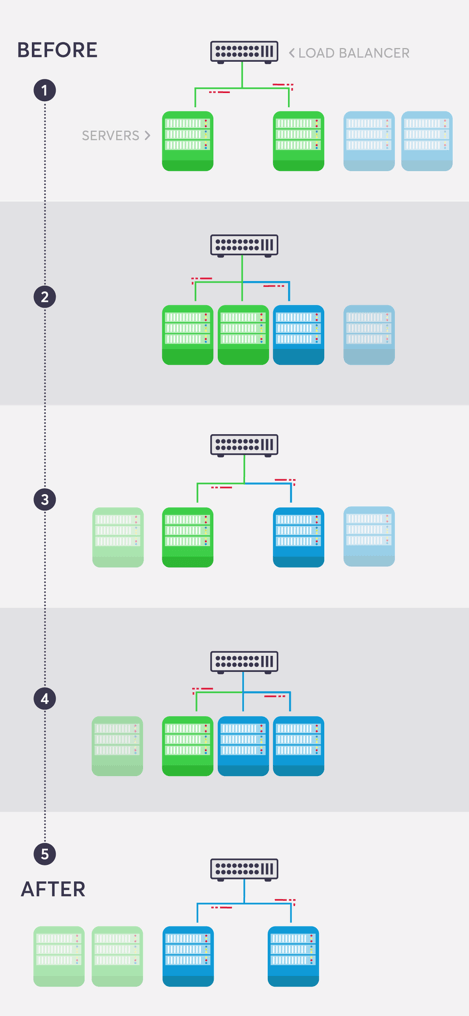
One thing to make sure though, is that your new code can run alongside your old code, because they will be running together side-by-side (see more on backward and forward compatibility below).
Note that you will need to use connection draining on your Load Balancer so requests processed by the old servers will have a chance to finalize before the old server is disconnected.
3. Monitor Your Environments With the Correct Alerts
Monitoring production is obvious, but monitoring the the non-production environment is also important - you want to catch those issues before they reach production, right? However, the non-production monitoring is less critical - you don’t want to wake up at night because of an issue on this environment, you just want to be aware of it the next morning.
Since the same environment can play both as production and non-production - you will need an easy way to toggle the alerting between the two states. This can be achieved by using a different API token for production/non-production reporting to your APM solution, or by programmatically changing the alert policy on the APM of an environment when its role changed.
4. Automate Whenever Possible
When doing blue-green testing, it is critical to automate as many actions as possible in the switch process, instead of doing a manual set of actions.
This has huge benefits:
- Quicker - the switch will happen faster if its steps are automated
- Easier - nothing needs to be remembered - just press a button
- Safer - manual work is more error prone
- Enables self-service - having a switch button running an automated script enables everyone with the right permissions to do it, without being dependant on someone that knows the exact steps that need to take place.
5. Make Your Code Backward and Forward Compatible
Because new and old versions are going to run side-by-side during the switching process, it is important to make sure both versions can co-exist. Take a database schema change for example; in many cases the same code will not be able to work with an altered schema.
In order to avoid downtime, you can break the update into a few “mini-updates”. For example, let’s say you’re changing a database field name from “user_name” to “username”.
This type of release will require the following steps:
- Release an intermediate version of the code, that can find and work with both “user_name” and “username” with some logic around it.
- Run data migration - rename the field to “username” across the all records/documents in the database (this can take seconds or days, it depends on the the dataset size)
- Release the final version of the code, supporting only “username”, and remove completely the old code supporting “user_name”.
Blue-Green Deployment & Testing in the Cloud
If your servers run in the cloud, there is an interesting variation of the Blue-Green deployment and testing method in which instead of going back and forth between two static environments, you can just create the next environment from scratch. This is possible if you have good automation and configuration management scripts that enable you to launch a new environment from scratch. After the switch, you can simply terminate the old environment altogether, and recreate it when the next release time comes.
This process is also valuable for avoiding the danger of servers becoming snowflakes, which are servers that have a unique configuration set that isn’t documented anywhere. Once these snowflakes get erased for some reason, you have no easy way to properly recreate them.
Whatever you choose to do, it’s worth following the newest blue-green test and release methodologies, to ensure your release is as smooth as it can be. Anyway, make sure you conduct load tests on your environment, but not on your production database without properly preparing for it and choosing the correct time window.