Blog
October 23, 2022

JMeter correlation is an important process, especially in load testing. In this blog, you'll get a complete overview of correlation in JMeter — and learn how to make it faster.
What is JMeter Correlation?
JMeter correlation is the process of capturing and storing dynamic responses from the server and passing them on to subsequent requests. If this important process is not handled correctly, the script is rendered useless.
From a testing point of view, it is necessary to identify which response is dynamic and which is static (the data stays the same for iterating requests). Typically every HTTP web performance test involves data correlation. You can ignore correlation only if you are testing static content pages, like some homepages and contacts. In other cases, you can’t avoid correlation handling at some point of the test.
To better clarify this point, here are some examples:
1. Static Content
The test requires evaluating the response time of static content with a specific network condition (e.g. proxy, gateway, etc). - When the specification is for static text in the response, there is no need for correlation, because the requirement focuses on the invariance of the content response.
2. Content Creation
The test requires that after creating a post on a blog, the user can perform one of many different actions. - Correlation is definitely involved in this step because the “creation” action involves dynamic content that must be handled (eg. page Id, url path, etc).
3. Cookies
After user authentication, the created session cookie must be… - No correlation step is necessary here because this step has authentication cookies, which can be handled with JMeter’s “HTTP Cookie Manager” component. In terms of data, this actually is a correlation, but JMeter already has a component that can handle this kind, so we don’t need to correlate ourselves.
4. Session ID
When a user lands on a web application, the server assigns her/him a session id. This id is used by the application to handle the user’s interaction. - This situation quite surely involves correlation, so it's necessary to investigate which application logic should be replicated, with correlation, in the successive requests.
5. User Navigation
During user navigation, the application assigns a specific condition to a cookie that alters the successive navigation steps - this one is tricky! If the information handled in the cookie is read from the cookie cache, you can handle the cookie (as already seen) with the “HTTP Cookie Manager” and not correlate. In any other case, this is quite surely a correlation activity.
Back to top
Example: Manual Correlation in JMeter
Manual correlation means that the developer manually discovers correlation points in the test flow and maps the values to be replaced in consecutive requests.
Correlation in Apache JMeter™ is handled in two steps:
- Extracting dynamic data from a key request and assigning it to variable (e.g. “Add -> PostProcessor” components like the “Regular Expression Extractor”).
- Reusing a variable in every occurrence that involves dynamic data.
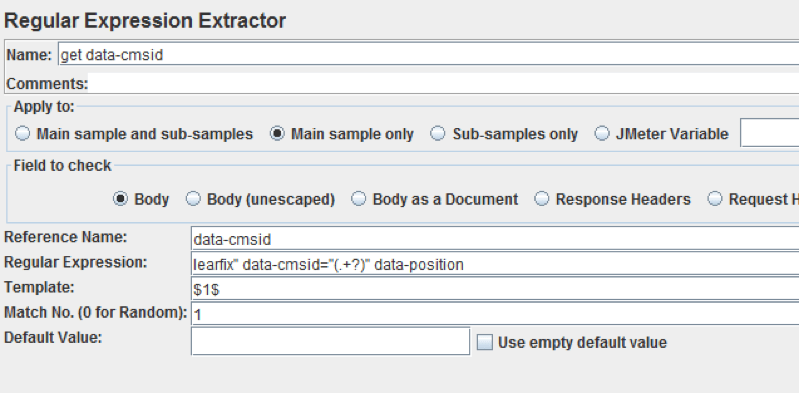
In the picture above you can see a “Regular Expression Extractor”, which extracts information from the body of the previous sample. Following this component, the successive requests can use the variable ${data-cmsid}, which will be dynamically mapped during execution. Learn more about how to manually correlate from this blog post.
This procedure is the common way to manually correlate with JMeter. It requires a deep investigation of the application to see where correlation is required.
Back to topHow to Make JMeter Correlation Easier
If you have a small script with only a few correlation points, you can correlate manually. But when your script is large and has a lot of correlations, handling tends to be time consuming and error prone for manual correlation.
Based on my experience, before starting to work on a potential “large script” with a lot of correlation points, it’s better to improve your analysis on the test requirements. You can do that by breaking down the large test into smaller test requirement subsets. If possible, each subset should be atomic, in term of developing and execution.
The final scope of the breakdown process is to have a small script that can be aggregated/sequenced into a final run scenario, maybe even directly in JMeter’s UI. However, this breakdown process requires time and effort, which come at a cost.
It would be much easier if correlation could be automated.
Auto-Correlation in JMeter
JMeter does not provide a native auto-correlation feature in its desktop application. However, you can use BlazeMeter’s free SmartJMX, which is included in the BlazeMeter Proxy Recorder. The recorder generated a JMX script, based on a recorded scenario, which is automatically correlated.
Auto-Correlation in SmartJMX Key Points
- SmartJMX is free and part of Blazemeter’s Proxy Recorder Technology.
- The Proxy Recorder Technology does not require installation because it is entirely on the web workspace.
- SmartJMX supports HTTP web recording for web, mobile browsers and native mobile apps. It’s suitable for any application based on HTTP.
- After recording, the JMX file is available for post processing on your local JMeter. After recording your script, the SmartJMX button appears. By clicking on it you will get a JMX file with all the correlation points automatically identified.
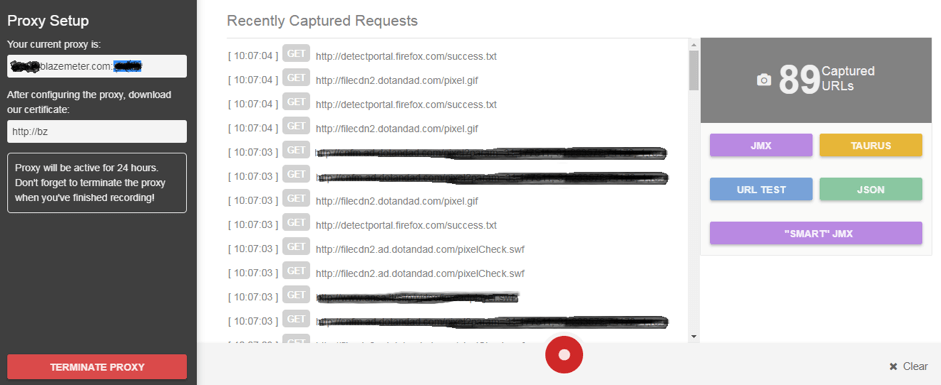
Since correlation is such an important part of scripting, it’s recommended to automate the process, to avoid manual errors and to save time.
Now that you’ve covered correlations, expand your JMeter knowledge with our free BlazeMeter University. We offer completely free basic and advanced JMeter training.