Blog
December 6, 2021

In this article, we are going to look at how to Apache Kafka testing by using Apache JMeter™. First of all, let us study what Kafka is and give a few definitions we will need for further work.
Back to topWhat Does Apache Kafka Do?
Kafka is a distributed streaming platform that functions as a hybrid of a distributed database and a message queue. It is widely known for its features and is used by many large companies to process terabytes of information.
Kafka solves the problem of interaction between these producers and consumers. It sits between these services, while collecting the data from the producers, storing them in a distributed repository of topics and giving each consumer the data by subscription. Kafka is launched as a cluster consisting of one or several servers, each of which is called a broker.
In a large distributed system, there are usually a lot of services that generate different events: logs, monitoring data, suspicious user actions, and so on. In Kafka, these are called producers. On the other hand, there are services that need the generated data. These are called consumers.
Apache Kafka is well-known across enterprise organizations. For example, in LinkedIn Apache Kafka is used to stream data about user activity, and Netflix uses it for data collection and buffering for downstream systems like Elasticsearch, Amazon EMR, Mantis etc.
Back to topThe Benefits of Kafka Testing
Let’s look at some of Kafka’s features that are important for load testing:
- A long message storing time - a week, by default
- High performance, thanks to sequential I/O
- Convenient clustering
- Enhanced observability means better insight into consumer lag, broker throughput, and under-replicated partitions
- High availability of data due to the capability to replicate and distribute queues across the cluster
- Not only is it able to transfer data, but it can also process it by using Streaming API
As a rule, Kafka is used to working with a very large amount of data. Therefore, the following aspects should be paid attention to during load testing:
- Constantly writing the data to the disk will affect the capacity of the server. If insufficient, it will reach a denial of service state.
- In addition, the distribution of sections and the number of brokers also affects the use of service capacity. For example, brokers may simply not have enough resources to process the data stream. As a result, the producers will exhaust local buffers for storing messages, and part of the messages may be lost.
- When the replication feature is used, everything becomes even more complicated. This is because its maintenance requires even more resources, and the case when brokers refuse to receive messages becomes even more possible.
Data that is processed in such huge amounts, can be very easily lost, even though most processes are automated. Therefore, testing of these services is important and it is necessary to be able to generate a proper load.
To demonstrate load testing Apache Kafka, it will be installed on Ubuntu. Besides, we will use the Pepper-Box plugin as a producer. It has a more convenient interface to work with message generation than kafkameter does. We will have to implement the consumer on our own, because no plugin provides consumer implementation, and we are going to use the JSR223 Sampler to do that.
Back to topHow to Set Up Your Kafka Testing
Configuring The Producer: Pepper-Box
To install the plugin, you need to download the jar file, then put it in the lib/ext folder and restart JMeter.
This plugin has 3 elements:
- Pepper-Box PlainText Config allows building text messages according to a specified template.
- Pepper-Box Serialized Config allows building a message that is a serialized java object.
- PepperBoxKafkaSampler is designed to send the messages that were built by previous elements.
Let us look at each of them.
Pepper-Box PlainText Config
To add this item, go to the Thread group -> Add -> Config Element -> Pepper-Box PlainText Config
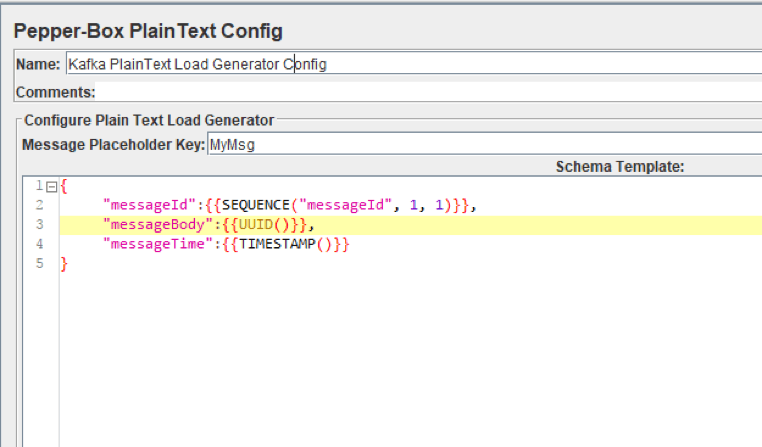
As you can see in the picture above, the element has 2 fields:
- Message Placeholder Key - a key that will need to be specified in the PepperBoxKafkaSampler to use the template from this element.
- Schema Template - a message template in which you can use JMeter variables and functions, and also plugin functions. The structure of the message can be anything, from plain text, to JSON or XML.
For example, in the screenshot above, we are passing the JSON string as a message, using several plugin functions: to specify the message number, to specify the identifier and the sending timestamp.
Pepper-Box Serialized Config
To add this element, go to Thread group -> Add -> Config Element -> Pepper-Box Serialized Config
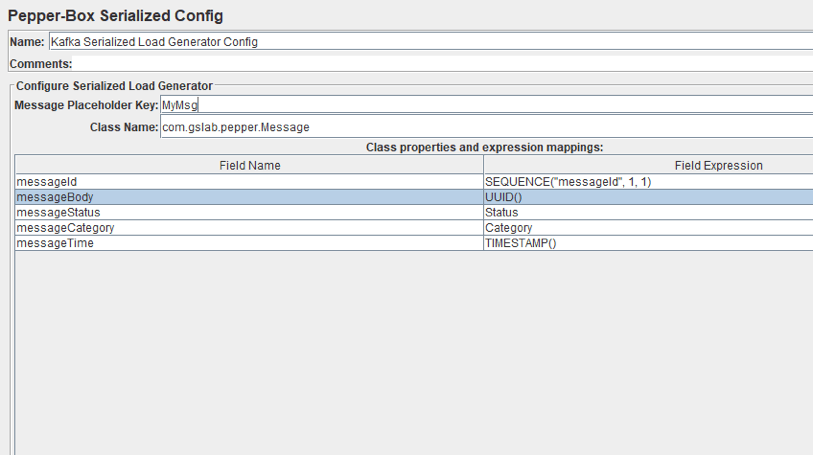
As you can see in the picture above, the element has a field for the key and the Class Name field, which is intended for specifying the Java class. The jar file with the class must be placed in the lib/ext folder. After it is specified, the fields with its properties will appear below, and you can assign desired values to them. We repeated the message from the last element, but it will be a Java object this time.
PepperBoxKafkaSampler
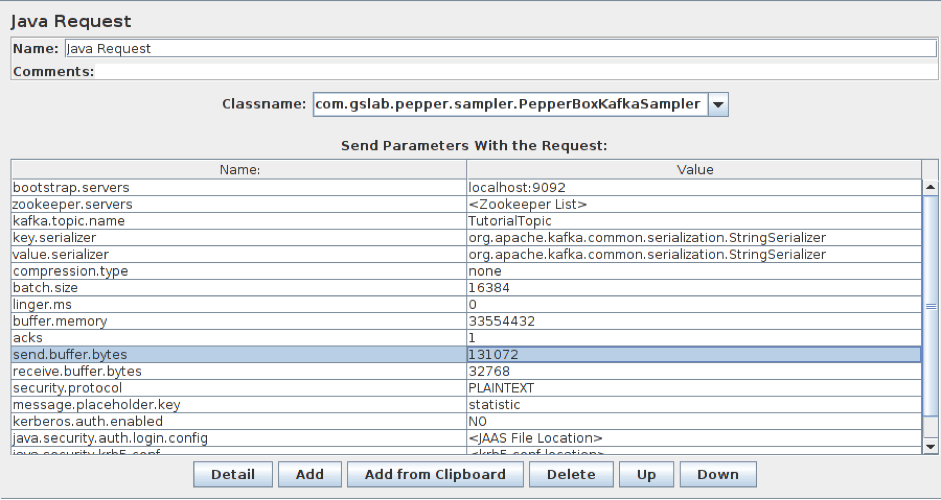
To add this element, go to Thread group -> Add -> Sampler -> Java Request. Then, select com.gslab.pepper.sampler.PepperBoxKafkaSampler from the drop-down list.
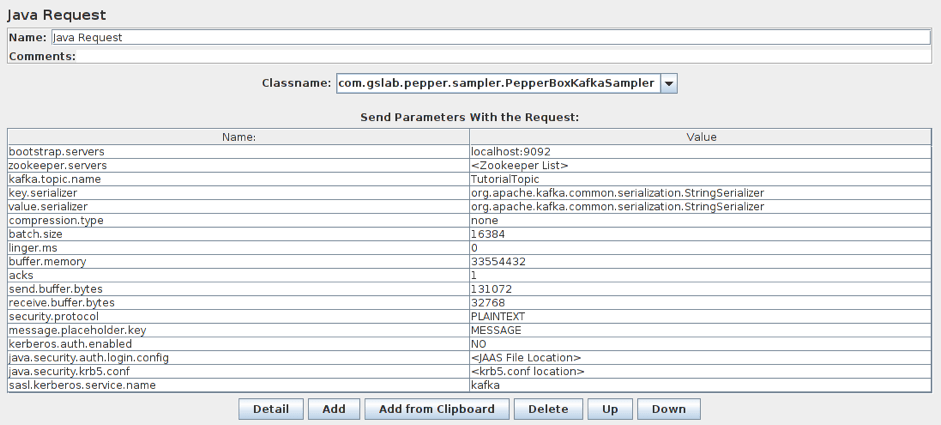
This element has the following settings:
- bootstrap.servers/zookeeper.servers - the addresses of brokers/zookeepers (a zookeeper is an interface that distributes the load from the producers between different brokers) in the format of broker-ip-1: port, broker-ip-2: port, etc.
- kafka.topic.name - is the name of the topic for message publication.
- key.serializer - is a class for key serialization. Leave it unchanged if there is no key in the message.
- value.serializer - is a class for message serialization. For a simple text, the field remains unchanged. When using Pepper-Box Serialized Config, you need to specify "com.gslab.pepper.input.serialized.ObjectSerializer".
- compression.type - is a type of message compression (none/gzip/snappy/lz4)
- batch.size - is the largest message size.
- linger.ms - is the message waiting time.
- buffer.memory - is the producer's buffer size.
- acks - is the quality of service (-1/0/1 - delivery is not guaranteed/the message will surely be delivered/the message will be delivered once).
- receive.buffer.bytes/send.buffer.bytes - the size of the TCP send/receive buffer. -1 - use the default OS value.
- security.protocol - is the encryption protocol (PLAINTEXT/SSL/SASL_PLAINTEXT/ SASL_SSL).
- message.placeholder.key - is the message key, which was specified in the previous elements.
- kerberos.auth.enabled, java.security.auth.login.config, java.security.krb5.conf, sasl.kerberos.service.name - are a field group responsible for the authentication.
Besides, if necessary, you can add additional parameters using the prefix _ before the name, for example, _ssl.key.password.
Configuring the Consumer
Now let us move on to the consumer. While it is the producer that creates the largest load on the server, the service has to deliver messages too. Therefore, we should also add consumers, to more accurately reproduce the situations. They can also be used to check whether all consumer messages have been delivered.
As an example, let us take the following source code and briefly touch upon its steps:
Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("group.id", group); props.put("enable.auto.commit", "true"); props.put("auto.commit.interval.ms", "1000"); props.put("session.timeout.ms", "30000"); props.put("key.deserializer", "org.apache.kafka.common.serializa-tion.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serializa-tion.StringDeserializer"); KafkaConsumer String> consumer = new KafkaConsumer String>(props); consumer.subscribe(Arrays.asList(topic)); System.out.println("Subscribed to topic " + topic); int i = 0; while (true) { ConsumerRecords String> records = con-sumer.poll(100); for (ConsumerRecord String> record : records) System.out.printf("offset = %d, key = %s, value = %s\n", record.offset(), record.key(), record.value()); }
1. A connection configuration is performed.
2. A topic is to be specified and a subscription is made to it.
3. Messages are received in the cycle of this topic and are brought out to the console.
This code with some modifications will be added to the JSR223 Sampler in JMeter.
Back to topReady to level up your JMeter load testing with Kafka? Start testing with BlazeMeter today for FREE!
How to Load Test Kafka With JMeter
Now that we have studied all the necessary elements for creating the load, let’s try posting several messages to the topic of our Kafka service. Let’s imagine that we have a resource from which the data on its activities are collected. The information will be sent as an XML document.
1. Add the Pepper-Box PlainText Config and create a template. The structure of the message will be as follows: Message number, Message-ID, Item ID which the statistics are collected from, the Statistics, Sending date stamp. The message template is shown in the screenshot below.
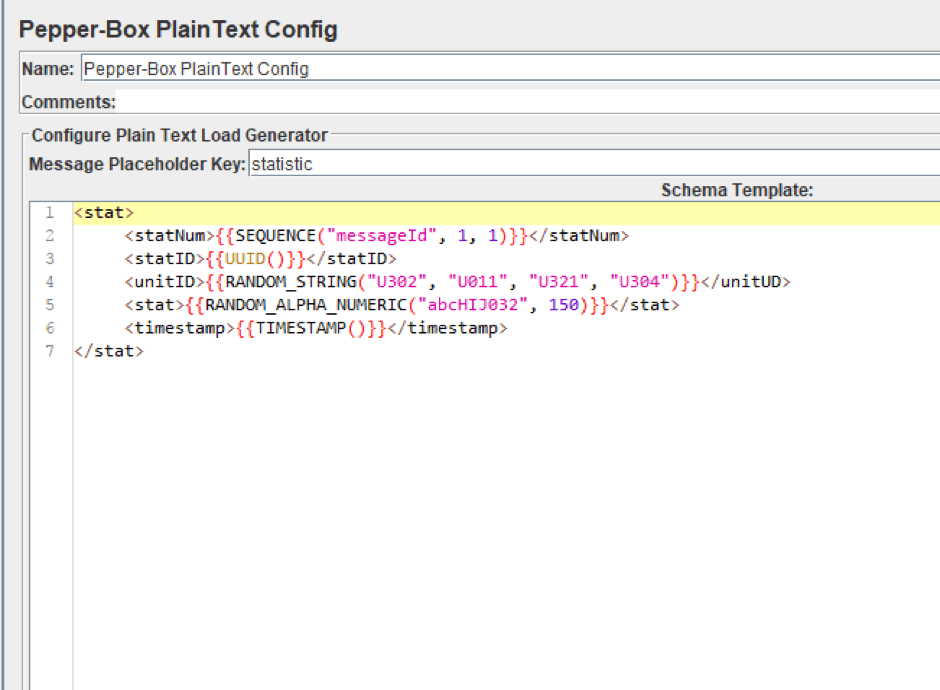
2. Add the PepperBoxKafkaSampler. In it, specify the addresses of bootstrap.servers and kafka.topic.name from our Kafka service. In our case, the address of broker is localhost:9092, topic for demonstration is TuttorialTopic. And we will also specify the placeholder.key from the template element from the previous step.
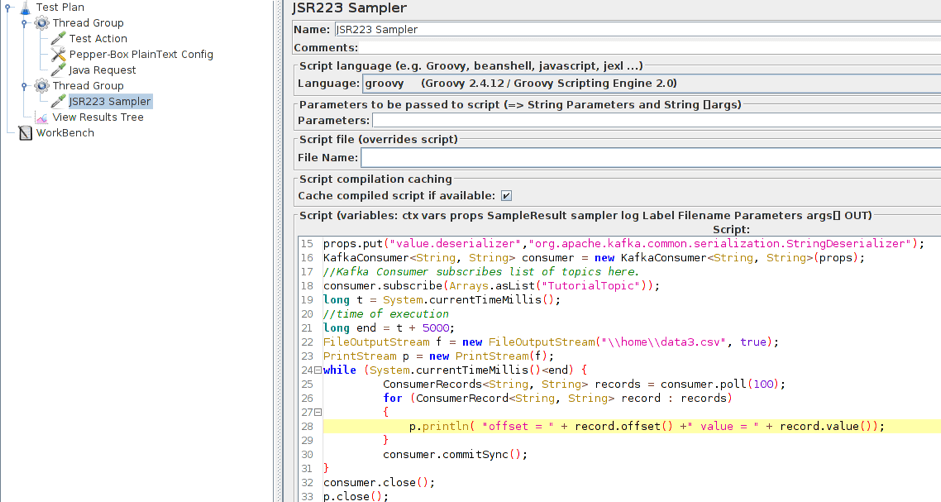
3. Add the JSR223 Sampler with the consumer code to a separate Thread Group. For it to work, you will also need a kafka-clients-x.x.x.x.jar files that contains classes for working with Kafka. You can find it in your kafka directory - /kafka/lib.
Here, we modified part of the script and now it saves the data to a file rather than displaying it in the console. This has been done for a more convenient analysis of the results. We also added the part that is necessary for setting the execution time of the consumer. For the demonstration it is setted at 5 seconds.
Updated part:
long t = System.currentTimeMillis(); long end = t + 5000; f = new FileOutputStream(".\\data.csv", true); p = new PrintStream(f); while (System.currentTimeMillis() { ConsumerRecords String> records = consumer.poll(100); for (ConsumerRecord String> record : records) { p.println( "offset = " + record.offset() +" value = " + record.value()); } consumer.commitSync(); } consumer.close(); p.close(); f.close();
Now the structure of the script looks as follows. Both threads work simultaneously. The Producers begin to publish messages to the specified topics. The Consumers connect to the topics and wait for messages from Kafka. When a message is received by the Consumer, it writes the message to a file.
4. Run the script and view the results.
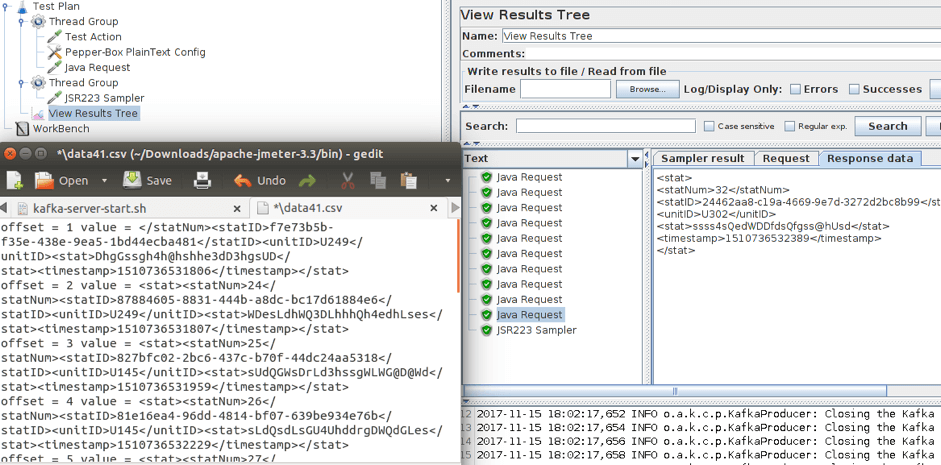
As you can see in the screenshot above, ten messages were sent. You can see the received messages in the opened file. After that, you just have to adjust the number of consumers and producers to increase the load.
Update:
If you get the following error when you try to run the scenario:

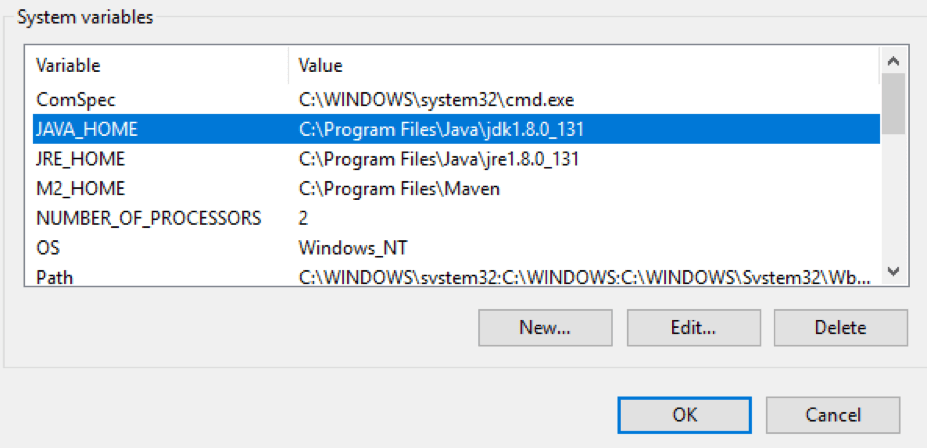
This means that JMeter uses JRE instead of JDK and you need to fix it, because JDK is a Pepper-box requirement.
Windows:
- Right click My Computer -> Properties -> Advanced -> Environment Variables
- Set path to JDK in Value field of JAVA_HOME Variable
- Run JMeter using jmeter.bat
Ubuntu:
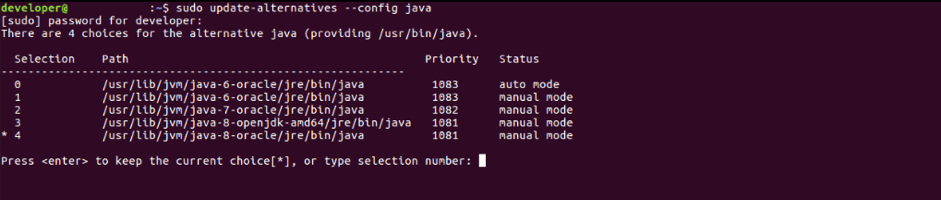
- Write sudo update-alternatives --config java and choose the right option (in this case it is 3).
- Run JMeter using jmeter.sh
It is worth reminding that the Apache Kafka is designed for a large number of connections, so you can simply reach the capacity limit of your network load generator. In which case, JMeter maintains the feature of distributed testing.
I would also like to note that there is no point using random data for messages during the testing, since they can differ in size significantly from the current ones, and this difference may affect the test results. Please, take test data seriously.
That’s it! You now know how to load test Apache Kafka with JMeter. To learn more advanced JMeter, check out our advanced course from BlazeMeter University.
Related Resources:
- Find Apache Kafka Solutions here!