Blog
November 13, 2021

By using scripts in Jenkins, releases of code can be pushed to the repository along with pipeline scripts in order to test newly-developed functionalities. This is done to ensure no bugs were introduced and that the application can perform with at least the same response times as the previous code. So, you can develop your pipeline script to execute automated tests only for specific flows and run performance tests by invoking Apache JMeter™ only for the desired test cases.
In this post, we will discuss the Jenkins Scripted Pipeline (Pipeline as Code) in detail, while explaining its structure and providing examples of how to use it.
Back to topWhat is the Scripted Pipeline in Jenkins?
A Jenkins Scripted Pipeline is a sequence of stages to perform CI/CD-related tasks that can be specified as code, enabling you to develop a pipeline script and add it to your code repository so you can version it.
Plus, the pipeline functionality comes right out of the box from Jenkins 2.0 onward, meaning that no configuration needs to be made to be able to create them.
Pipelines are a suite of Jenkins plugins. Pipelines can be seen as a sequence of stages to perform a wide range of tasks that help provide continuous releases of your application. The concept “continuous” is relative to your application and/or environment: In some cases releases can be performed on a daily basis while for others could be weekly, depending on your business needs. In some situations, a critical fix, for example, it would be desirable to have your environment ready to release your application as soon as possible. Pipelines provide a way to do this through an automated process.
In Jenkins, Pipelines are specified by using a specific DSL following almost the same structure as Groovy to specify its statements and expressions. This makes pipelines easy to use for Groovy savants.
Back to topPerformance testing for free? Performance testing for free. Try BlazeMeter today!
How to Create Your Jenkins Scripted Pipeline
With the introduction of the Scripted Pipeline, Jenkins added an embedded Groovy engine, making Groovy the scripting language in the Pipeline´s DSL.
Here are the steps you need to take to set up a Jenkins Scripted Pipeline.
1. First, log on to your Jenkins server and select “New Item” from the left panel:
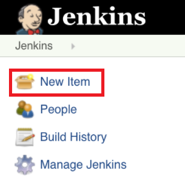
2. Next, enter a name for your pipeline and select “Pipeline” from the options. Click “Ok” to proceed to the next step:
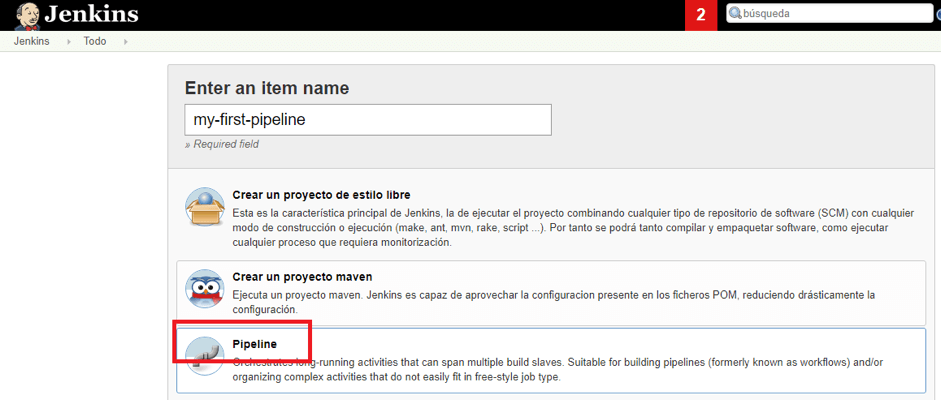
3. You can now start working on your Pipeline script:
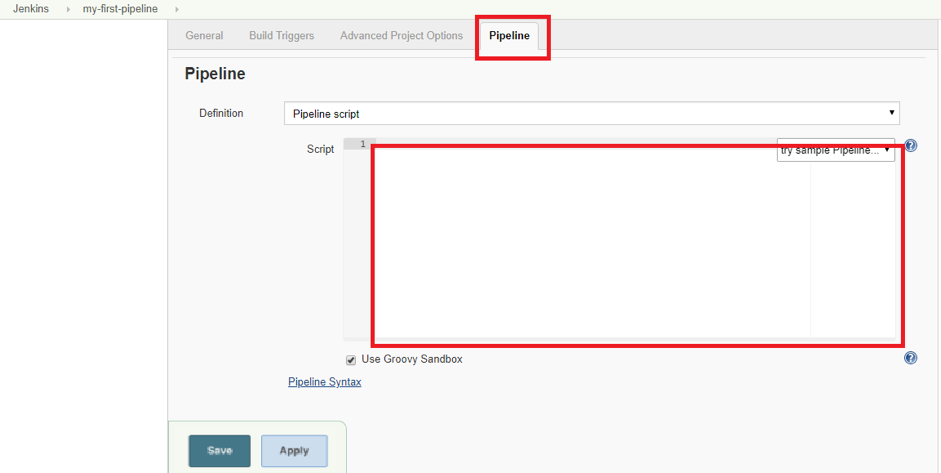
The red box in the middle is where you can start writing your script, which will be explained now.
Back to topCreating Your Jenkins Pipeline Script
Pipelines have specific sentences or elements to define script sections, which follow the Groovy syntax.
Node Blocks
The first block to be defined is the “node”:
node {
}
A “node” is part of the Jenkins distributed mode architecture, where the workload can be delegated to multiple “agent” nodes. A “master” node handles all the tasks in your environment. Jenkins agent nodes offloads builds from the master node, thus performing all the pipeline work specified in the node block. Detailed information on this can be found at Jenkins Distributed builds.
This block is not mandatory but it is desired and can be considered as good practice, since with the code included in this block, Jenkins will schedule and run all the steps once any node is available and creates a specific workspace directory.
Stage Blocks
The next required section is the “stage”:
stage {
}
Your pipeline will consist of several steps that can be grouped in stages. Among these stages you might have:
- Pull code from repository
- Build your project
- Deploy your application
- Perform functional tests
- Perform performance tests
Each of the these can include more than one action. For example, a stage to deploy your application can consist of copying the files to a specific environment for functional tests and to a dedicated server for performance tests; and once files are copied successfully, proceed to deploy it.
Each stage block specifies the tasks to be performed. For example, a full scripted pipeline might be:
node {
stage (‘Build’) {
bat "msbuild ${C:\\Jenkins\\my_project\\workspace\\test\\my_project.sln}"
}
stage('Selenium tests') {
dir(automation_path) { //changes the path to “automation_path”
bat "mvn clean test -Dsuite=SMOKE_TEST -Denvironment=QA"
}
}
}
This script has the following stages:
- Build stage:
- bat “msbuild…”: Builds the project by specifying a Visual studio solution file.
- Selenium tests stage:
- dir(automation_path): Changes the current directory to the value set on the automation_path variable.
- bat “mvn clean test … “: Invokes maven to perform tests specified in the suite “SMOKE_TEST” and using the values defined on “QA”. Also, the “clean” flag will clean the build.
Stage blocks are also optional, but they are recommended because they provide an organized way of specifying tasks to be executed in the script.
Jenkins provides an interface that generates pipeline sentences for predefined actions that can be added to any of the script stages. On your pipeline script page, click on “Pipeline Syntax” to access the following page:
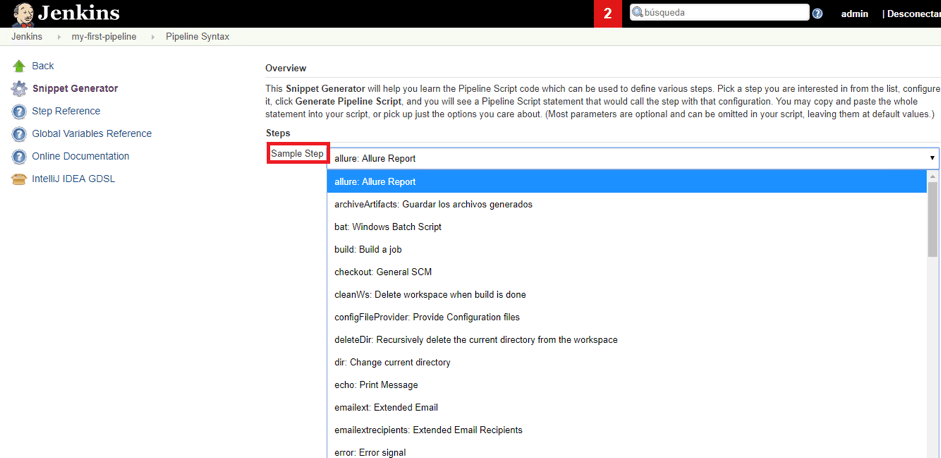
For example, to create a script command to execute a Windows batch file, select the following:
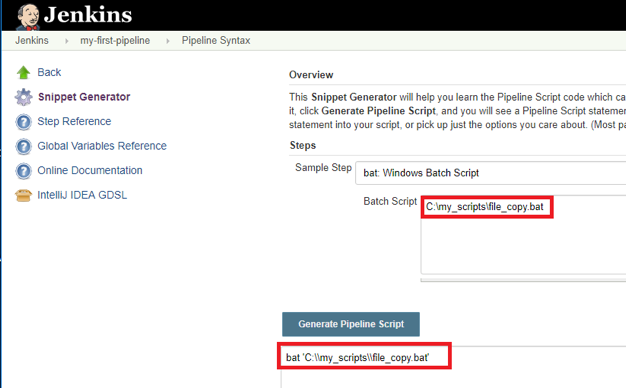
Clicking on “Generate Pipeline Script” will create the desired sentence that can be added to your script right away.
Back to topThe Jenkinsfile
Pipeline as code is based on the idea of being able to add the pipeline script to a code repository for source control and versioning. The text file containing the code of your pipeline is also known as a Jenkinsfile.
Writing your pipeline into a Jenkins file and make it part of your application repository for source control has several advantages: it can be reviewed/edited by other team members and the file can be versioned and included with your application builds.
Your Jenkinsfile can be edited through the Jenkins web interface or with a text editor, and you can also edit it with your prefered IDE, thus making it part of your project. Then, you can configure Jenkins to automatically poll your repo, while triggering new builds when updates to it are detected. This can be done through the following screen on your Project configuration under “Build triggers” section:
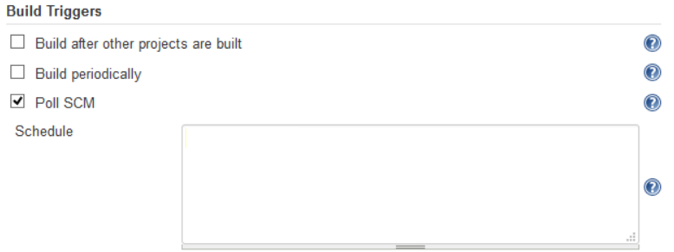
Enabling “Poll SCM”, allows you to enter a cron like expression in the Schedule text box. Configuring Jenkins to poll your repo is not a clean and efficient way to retrieve updates. Instead, Git Hooks is neat way of doing it. The document at Customizing Git - Git Hooks provides information on how to configure it.
Back to topJenkins Scripted Pipeline Security
Jenkins limits the execution of any Groovy script by providing a sandbox. The option “Use Groovy Sandbox”, shown below, is available in the Jenkins Scripted Pipeline tab, and it allows the scripts to be run by any user without requiring administrator privileges. In this case, the script is run only by using the internal accessible APIs (that allow you to develop your script by using Groovy).
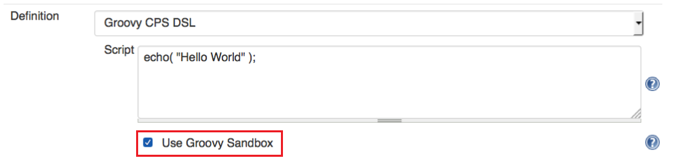
When unchecked, if the script has operations that require approval, an administrator will have to provide them. This method is known as “Script approval”. By default, all Jenkins pipelines run in a Groovy sandbox. If the option is checked and unauthorized operations are used, the script will fail when run. Both the whitelist and the blacklist of functions can be checked at Script Security’s built-in list. Please refer to In-process Script Approval for more information on this topic.
Back to topJenkins Scripted Pipeline vs. Declarative Pipeline
One of the latest Pipeline improvements is the Jenkins Declarative Pipeline, which is a bit different than the Scripted Pipeline that we have been discussing. Both are implementations of the pipeline as code, but the Declarative way is designed to make it easier to develop and maintain your code by providing a more meaningful syntax. These two enhancements are achieved by adding syntax elements allowing you to define a different pipeline skeleton.
Basically, a Jenkins scripted pipeline has the following skeleton:
node {
stage (‘Build’ {
//...
}
stage (‘Test’) {
//...
}
}
On the other hand, a declarative pipeline can be written by using more elements, as shown next:
pipeline {
agent any
stages {
stage(‘Build’) {
steps {
//…
}
}
stage (‘Test’) {
steps {
//…
}
}
}
}
The script has the elements “pipeline”, “agent” and “steps” which are specific to Declarative Pipeline syntax; “stage” is common to both Declarative and Scripted; and finally, node” is specific for the Scripted one.
- “Pipeline” defines the block that will contain all the script content.
- “Agent” defines where the pipeline will be run, similar to the “node” for the scripted one.
- “Stages” contains all of the stages.
Bottom Line
Learn how to use Jenkins for all of your testing needs for free from BlazeMeter University.
You can also integrate BlazeMeter into your Jenkins Pipeline. Try out running your performance tests in BlazeMeter by requesting a demo or putting your URL in the box below, and your test will start in minutes.