Blog
September 24, 2020

In this article, we will look at how to load test HBase with Apache JMeter™ without coding.
Back to topWhat is HBase?
HBase is a NoSQL database that provides real-time read/write access to large datasets, for instance, datasets of 1000 genomes. HBase is natively integrated with Hadoop, which is a Distributed File System with MapReduce mechanism.
HDFS (Hadoop Distributed File System) allows you to store huge amounts of data in a distributed and redundant manner. The distribution provides faster read/write access and the redundancy provides better availability. In addition, because of the nodes distribution that stores the data, we need a coordination service, which in this case is Zookeeper.
So, HBase stores large data sets on top of the HDFS file storage, and will aggregate and analyze billions of rows present in the HBase tables. For instance, HBase can be used in social network applications such as real-time data updates of user’s location.
If you do not know much about HBase, you can see their glossary. For the demonstration, we will deploy HBase on Ubuntu in a pseudo-distributed mode. This is like a normal distributed mode, but it allows you to deploy everything on one machine, for example, to test the configuration. Check out the installation instructions, too.
In JMeter, to create a load for HBase there is a Hadoop Set plugin, which you can install by using the plugins manager. This plugin has 6 elements, which we will look into below.
HBase Connection Config
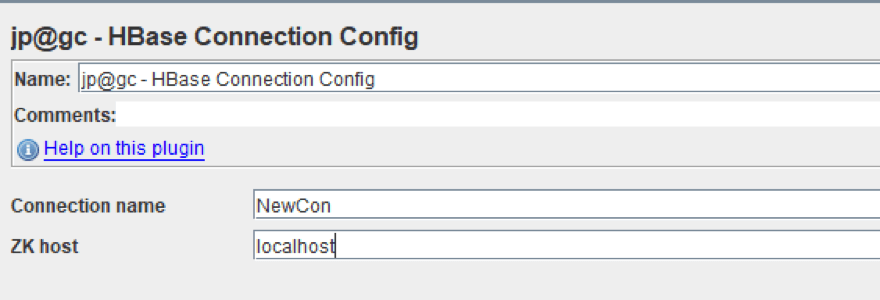
To add it: Right Click on Test Plan -> Config element -> jp@gc - HBase Connection Config
This Config element is used to configure the connection to our database.
- Connection name is the name we will use when getting information from our database.
- Zk host is the address of our coordination service: Zookeeper server.
HDFS Operations Sampler
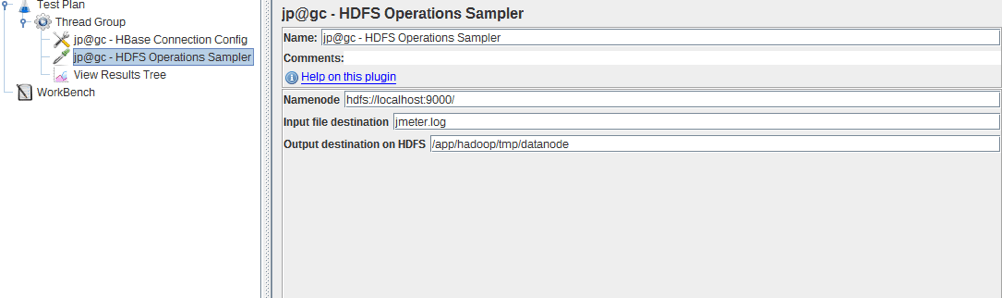
To add it: Right Click on Thread group -> Sampler -> jp@gc - HDFS Operations Sampler
This sampler is designed to copy files to the HDFS storage.
- Namenode is the Address of Hadoop Namenode, Default port is 8020.
- Input file destination is the path to the file, which we want to put in the HDFS storage.
- Output destination on HDFS is a path to the HBase storage.
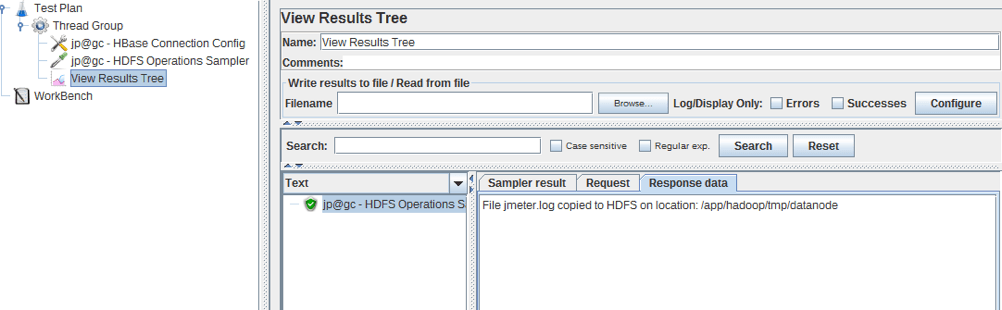
The response shows the name of the file and the location to which it has been copied.
Hadoop Job Tracker Sampler
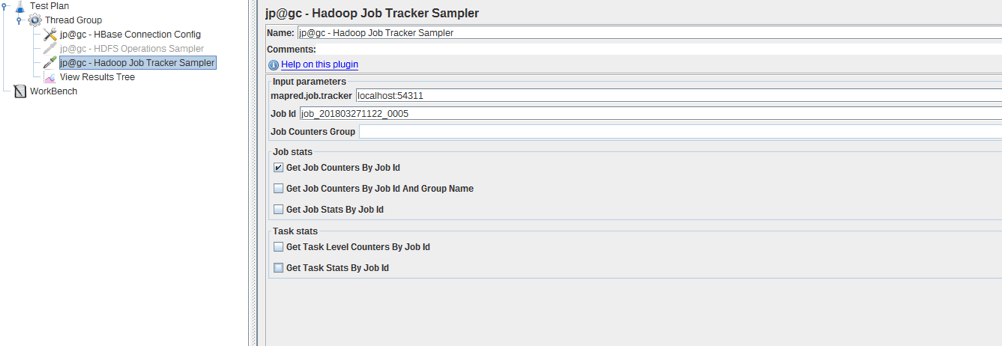
To add it: Right Click on Thread group -> Sampler -> jp@gc - Hadoop Job Tracker Sampler
This sampler can be used to get job or task counters and stats like read records, processed records or progress of a job by id and group names.
- mapred.job.tracker is the jobtracker url, the default port is 8082.
- job id is the id of the target job. The name of the job can be used too.
- Job Counters Group is an optional field that is used to Retrieve job counters by providing the job id and group name option.
- Job stats/Task stats is information that we want to get and ways of getting it.
The result is an XML message with the necessary information.
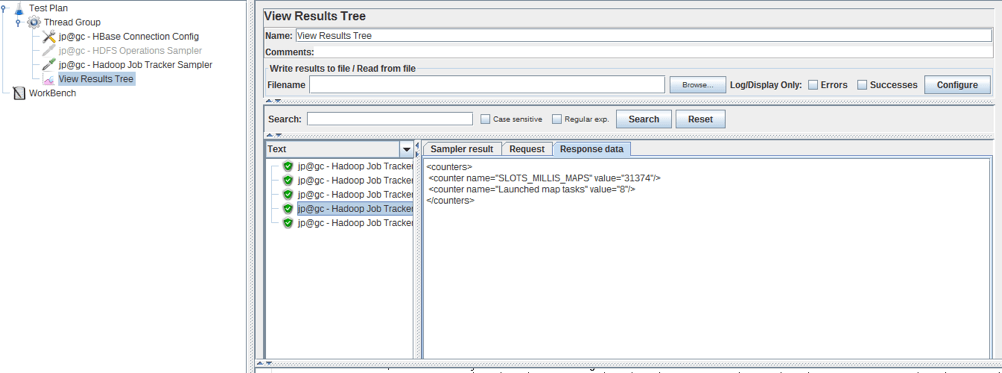
HBase CRUD Sampler
To add it: Right Click on Thread group -> Sampler -> jp@gc - HBase CRUD Sampler
This sampler provides the CRUD (Create/Update/Read/Delete) operation over HBase. Basically we can perform add/update/delete operation to the database by using this sampler. For this blog post we need to use Hbase Rowkey Sampler or HBase Scan Sampler.
- hbase.zookeeper.quorum is the address of the zookeeper. You can find the list of all addresses in conf/hbase-default.xml file if you installed Hbase right now or in conf/hbase-site.xml file if you are testing a configured Hbase.
- Hbase source table/Rowkey is the name of the table/rowKey of the specific record.
- Operations is choosing an operation and columns to apply.
- If Operations mode is checked, you can perform the operation to the last element in the selection.
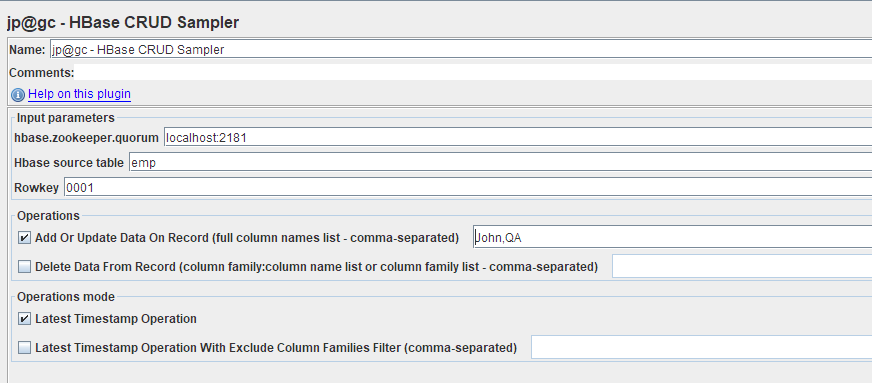
HBase Scan Sampler
To add: Right Click on Thread group -> Sampler -> jp@gc - HBase Scan Sampler
The scan sampler is used to retrieve single/multiple record with rowKeys or a filter from the HBase table.
- Connection name is the name from the HBase Connection Config
- Table is name of the table that we want to scan
- start rowKey/end rowKey is the interval for searching records. These are optional fields.
- Limit is the limit of the returning records;
- Filters are filters for searching. The filters should be separated by line breaks and presented in the following format: {column_family}:{qualifier}{= | != | < | > | <= | >=}{value}
For instance, we have the 2 following records:
| Row Key | Column Family: {Column Qualifier:Value} |
| 00001 | CustomerName: {‘FN’:‘John’, ‘LN’:‘Smith’, ‘MN’:’Timothy’} ContactInfo: {‘EA’:‘John.Smith@xyz.com’, ’SA’:’1 Hadoop Lane, NY 11111’} ‘Order’: {‘CN’:5, ‘P’:500} |
| 00002 | CustomerName: {‘FN’:‘Jane’, ‘LN’:‘Doe’, ContactInfo: {’SA’:’7 HBase Ave, CA 22222’} ‘Order’: {‘CN’:3, ‘P’:1500} |
Then we can retrieve these 2 rows using ‘Order:P>400’ filter or only the first row using ‘CustomerName:FN=John’.
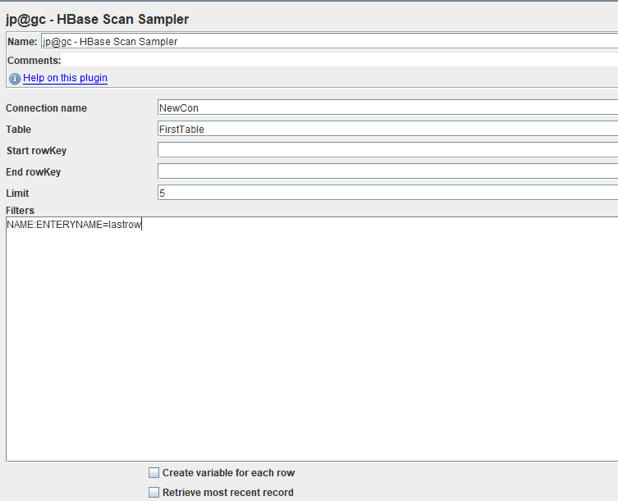
HBase Rowkey Sampler
To add it: Right Click on Thread Group -> Sampler -> jp@gc - HBase RowKey Sampler
The RowKey sampler is used to read a specific record by a rowKey of the HBase table. This sampler needs a HBase Connection Config to set the connection like HBase Scan Sampler.
- Connection name is the name from HBase Connection Config.
- Table/RowKey is the name of the table/rowKey of a specific record.
- If Retrieve the most recent record is checked, you will get only the last created record
- If Create variable for each row is checked JMeter will immediately write the result in a JMeter variable for later use in the script.
Other Elements Needed for HBase Testing
The script will depend on what you are testing at the moment, but in all cases you will need additional elements. You can use Loop Controller or the Runtime Controller to create a loop and CSV Data Set Config to parameterize requests.
For instance, the script for testing the recording to the database will look like this:
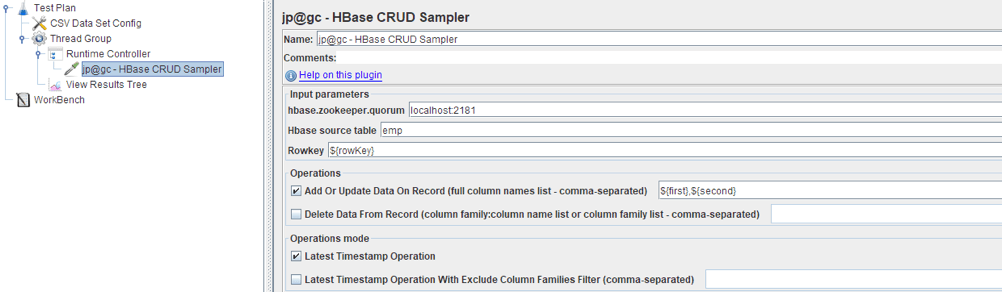
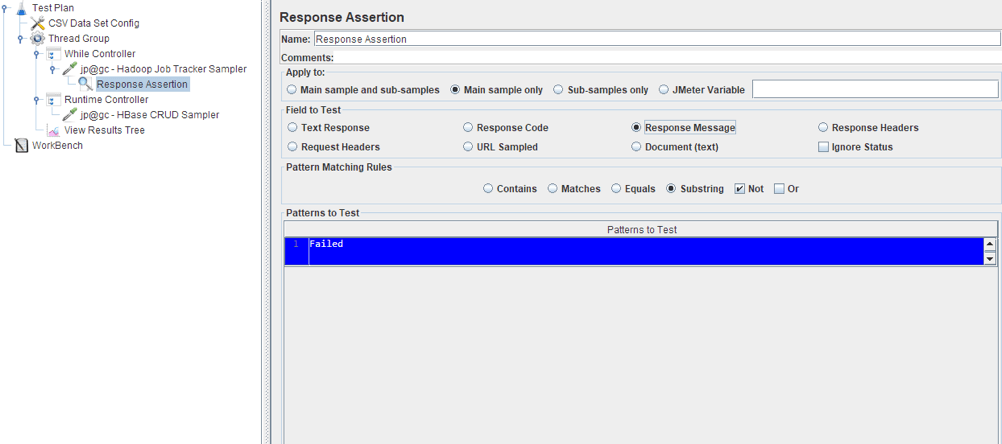
If you want to avoid the job from failing, you can add a Response Assertion, which will check the response body. If it indicates that the work failed, then the sampler will be marked as unsuccessful. It will look like this:
Performance Notes
- In any production environment, HBase can contain more than 5000 nodes, with only the Hmaster node acting as a master server to all region servers. If Hmaster shuts down, the whole cluster will only be able to be recovered after a long time. We can create an additional master node, but only one can be active. The activation of the second Hmaster will take a large amount of time if the main Hmaster shuts down. So, the Hmaster node is a performance bottleneck and its work should not be disturbed.
- In HBase, we cannot implement any cross data and joining operations. In fact we can implement the joining operations using MapReduce, but it is a very difficult and costly operation and can take a large amount of resources and time. So, if you have something like that on your project, be sure to pay attention to it.
- Another shortage of HBase is that we cannot have more than one indexing element in the table - we have only one primary key and it is rowKey column. Consequently, performance will be slower if we are trying to search by more than one field or by something other than the rowKey field. This problem can be resolved by integrating with Apache SOLR and Phoenix, but the result is that we will have new services in our system.
- More servers should be installed for distributed cluster environments (like each server for NameNode, DataNodes, ZooKeeper, and Region Servers). Performance-wise it requires high memory machines. Thus, costs and maintenance are also higher.
- HBase is CPU and Memory intensive with large sequential input or output access, while Map Reduce jobs are primarily input or output bound with fixed memory. HBase integrated with Map-reduce jobs will result in unpredictable latencies.
- As you have probably noticed, HBase is associated with a lot of other applications, like Hadoop, Zookeeper, Phoenix etc. Therefore, when using each of them, it is worth considering the load capacities of each of them. After all, with such a large number of services, the bottleneck can be something other than HBase.
- Besides, for performance monitoring in HBase you have HTrace. By using this tool you can trace each request through the whole cluster and get information about each participating node.
Back to top
New Versions of Hadoop and HBase
If you try to use this plugin with the new version of Hadoop (2.x +), you will get the following error: Server IPC version 9 cannot communicate with client version 4. This plugin works with Hadoop 1.2.1 and lower, because in later versions of Hadoop some libraries have been updated and replaced. As a result, the plugin cannot interact with the new version of the application, because it uses the old library (hadoop-core.jar) which is no longer supported.
1. Therefore, you need to download the source code and replace one dependency in .pom file:
<dependency> <groupId>org.apache.hadoopgroupId> <artifactId>hadoop-coreartifactId> <version>1.1.2version> dependency>
With these dependencies:
<dependency> <groupId>org.apache.hadoopgroupId> <artifactId>hadoop-commonartifactId> <version>3.0.0version> dependency> <dependency> <groupId>org.apache.hadoopgroupId> <artifactId>hadoop-mapreduce-client-coreartifactId> <version>3.0.0version> dependency>
Versions of the libraries should match the versions of your Hadoop.
2. Identify the necessary dependencies and put them in the /lib folder along with hadoop-common and hadoop-mapreduce-client-core.
3. Implement the missing methods in one plugin compilation verification test, or simply delete the tests (not recommended).
4. Compile jar and put it in /lib/ext folder.
Now, you can run the tests like I showed above.
That’s it! You can now load test HBase with JMeter. To learn more advanced JMeter, go to our free JMeter academy. You can also upload your JMX file to BlazeMeter and enjoy collaboration, advanced reporting, and continuous integration compatibility.