Blog
July 17, 2025

The largest risk when releasing a new version to production is finding errors and issues, small or large, a moment after the release. Even if you thoroughly test the new features on your load testing environments, they might behave differently in production and cause malfunctions and glitches.
But there is a solution: blue green deployment is a risk-reducing method for deploying new versions to production. This is done by working with two identically configured environments — one production (publicly facing) and one internal — and switching between them.
This testing methodology provides organizations with a safety net during deployments for rapid rollbacks and reducing downtime. By implementing proper blue-green deployment testing strategies, development teams can achieve smoother releases and enhanced system reliability.
In this blog, you will learn proven blue-green deployment testing strategies to minimize release risks, reduce downtime, and ensure smooth software deployments.
Back to topWhat Is a Blue Green Deployment?
Blue-green deployment is a development strategy that utilizes two identical production environments for testing and deployment purposes. One environment (designated as "green") serves as the live production system, while the other environment (designated as "blue") functions as an internal staging environment accessible only to the organization.
The naming convention — blue and green — provides a consistent reference system regardless of which environment currently serves production traffic. Some organizations refer to this approach as A/B deployments or Red/Black deployments, but the core principle remains the same: maintaining two identical environments that can seamlessly switch roles.
Both environments connect to the same database infrastructure and maintain identical configurations. The primary distinction lies in traffic routing: the green environment receives all user traffic while the blue environment remains isolated for internal testing and validation.
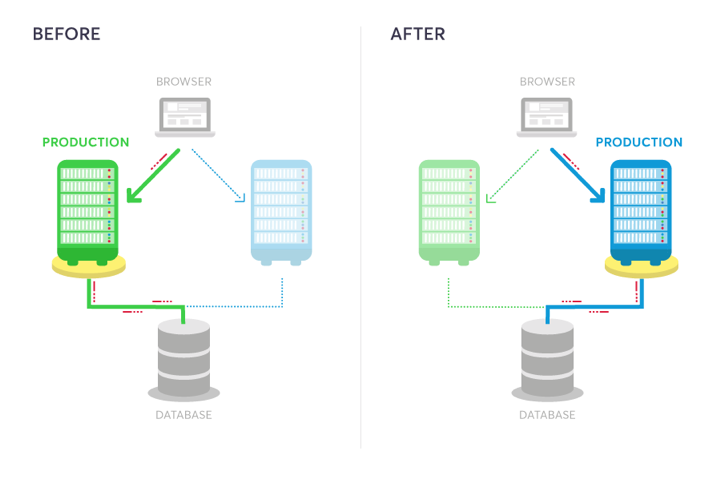
This approach eliminates the traditional gap between staging and production environments where differences in configuration or data volume can mask critical issues until after deployment.
Back to topHow Blue Green Deployment & Blue Green Testing Works
The blue-green deployment process follows a structured approach that prioritizes thorough testing before exposing new code to production traffic.
Initial Deployment Phase
Development teams deploy the release candidate version to the blue (internal) environment after passing standard development and QA tests. This release candidate represents code that has met minimum quality gates and is ready for final production validation.
Testing and Validation
The blue environment serves as the final testing ground where teams execute comprehensive test suites including automated functional tests, integration tests, and manual validation procedures. Any discovered bugs receive immediate fixes and redeployment within the controlled blue environment.
Traffic Switching
Once testing confirms the new release functions correctly, teams initiate the switch process. The blue environment transitions to become the live production system while the green environment assumes the internal testing role. This switch occurs seamlessly from the user perspective with no visible disruption to service.
Rollback Capability
If issues emerge after the switch, teams can instantly revert to the previous version by switching traffic back to the green environment. This immediate rollback capability significantly reduces the impact of deployment-related issues. In production, rollbacks are increasingly automated based on service-level objectives (SLOs) tracked via observability platforms (Datadog, New Relic, Prometheus).
Real-World Example
Consider a scenario where developers add a new feature requiring a database query. In smaller testing environments, the query performs adequately. However, when deployed to production with larger datasets, the query may execute slowly due to missing database indexes. Blue-green deployment allows teams to identify and resolve this performance issue before users experience the degradation.
It is important to note that today, many teams use Kubernetes and service meshes (e.g., Istio, Linkerd, Consul) to implement blue-green or canary deployments at the network layer with minimal manual effort. Tools like Argo Rollouts and Flagger offer native support for blue-green and canary strategies in Kubernetes environments for seamless traffic routing, gradual rollout, and automated rollback based on SLOs.
Back to topBlue-Green Deployment Best Practices
1. Choose Load Balancing Over DNS Switching
DNS-based switching introduces propagation delays that can extend for hours and result in inconsistent user experiences. Some users continue accessing the old environment while others reach the new one. This creates a lack of control over traffic distribution.
Load balancing provides superior control by maintaining consistent DNS records that point to the load balancer. Teams modify only the backend server configuration so there is immediate and complete traffic redirection to the new production environment.
2. Execute a Rolling Update
Simultaneous switching of all servers from old to new versions can cause service disruptions. Rolling updates mitigate this risk by gradually transitioning servers one at a time.
This process involves adding one new server while retiring one old server — repeating until all servers run the new version (see image below). Rolling updates require careful attention to code compatibility because new and old versions operate simultaneously during the transition period.
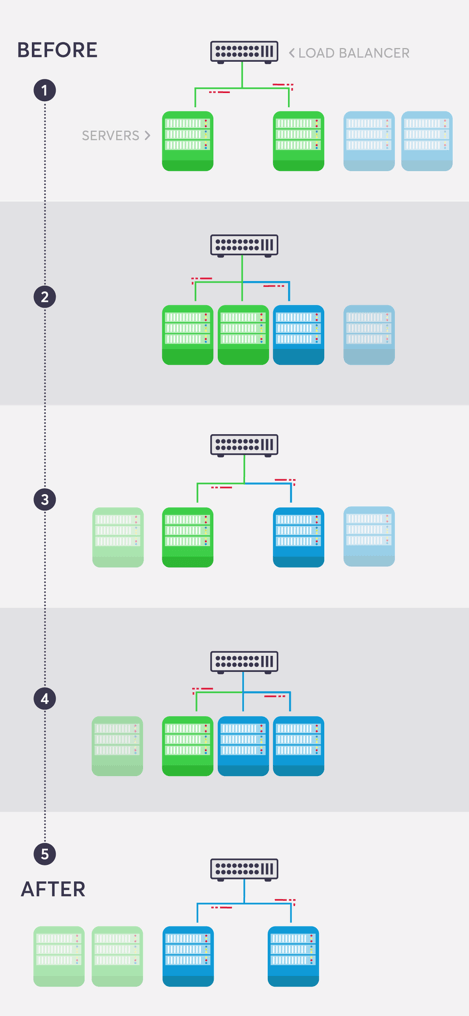
Connection draining on load balancers ensures that in-flight requests complete processing before servers disconnect and prevents request failures during the transition.
3. Monitor Your Environments With Appropriate Alerts
Production monitoring remains critical, but non-production environment monitoring serves equally important purposes for early issue detection. However, alert criticality levels should differ between environments.
Production alerts require immediate attention — including after-hours notifications for critical issues. Non-production alerts should provide awareness without causing unnecessary urgency to allow teams to address issues during regular business hours.
Since environments switch between production and non-production roles, teams need mechanisms to toggle alert policies accordingly. This can be achieved through separate API tokens for different monitoring states or programmatic alert policy updates when environment roles change.
4. Automate the Switch Process Whenever Possible
Manual switching processes introduce human error risks and create dependencies on specific team members. Automation provides multiple advantages:
Faster execution.
Reduced complexity.
Enhanced safety.
Self-service capabilities for authorized personnel.
Automated switching enables teams to execute deployments through simple button presses rather than complex manual procedures. This consistency reduces errors and allows more team members to participate in deployment activities.
5. Ensure Code Compatibility
Because new and old versions are going to run side-by-side during the switching process, it is important to make sure both versions can co-exist. Take a database schema change for example; in many cases the same code will not be able to work with an altered schema.
In order to avoid downtime, you can break the update into a few “mini-updates”. For example, let’s say you’re changing a database field name from “user_name” to “username”.
This type of release will require the following steps:
- Release an intermediate version of the code, that can find and work with both “user_name” and “username” with some logic around it.
- Run data migration - rename the field to “username” across the all records/documents in the database (this can take seconds or days, it depends on the the dataset size)
- Release the final version of the code, supporting only “username”, and remove completely the old code supporting “user_name”.
Blue-Green Deployment & Testing in the Cloud
Cloud environments enable enhanced blue-green deployment strategies through infrastructure automation capabilities. Rather than maintaining static environments, teams can create new environments from scratch for each deployment.
This approach requires robust automation and configuration management scripts that can provision complete environments programmatically. After successful switching, teams can terminate the old environment entirely and recreate it for the next deployment cycle.
Benefits include:
- Elimination of server "snowflakes" - unique configurations that lack proper documentation.
- Consistent environment provisioning through automated scripts.
- Cost optimization by running only necessary infrastructure.
- Reduced configuration drift between deployments.
Cloud-based blue-green deployment also supports more complex testing scenarios such as load testing with production-like data volumes and network conditions.
Back to topBottom Line
Blue-green deployment testing strategies provide organizations with powerful risk mitigation capabilities while maintaining continuous delivery objectives. Success depends on proper implementation of load balancing, rolling updates, comprehensive monitoring, automation, and code compatibility practices.
BlazeMeter enhances blue-green deployment success by providing comprehensive testing capabilities that validate performance across both environments. Load testing ensures that new deployments can handle production traffic volumes while monitoring capabilities provide visibility into application behavior during and after deployments.
Organizations implementing blue-green deployment strategies should prioritize thorough testing in non-production environments before switching traffic. BlazeMeter's continuous testing platform enables teams to identify performance bottlenecks, validate functionality, and fortify system reliability before exposing new code to users.